

library_name: transformers
tags:
- reward
- RM
- Code
- AceCode
- AceCoder
license: mit
datasets:
- TIGER-Lab/AceCode-89K
- TIGER-Lab/AceCodePair-300K
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-7B-Instruct
🂡 AceCoder
Paper | Github | AceCode-89K | AceCodePair-300K | RM/RL Models
We introduce AceCoder, the first work to propose a fully automated pipeline for synthesizing large-scale reliable tests used for the reward model training and reinforcement learning in the coding scenario. To do this, we curated the dataset AceCode-89K, where we start from a seed code dataset and prompt powerful LLMs to "imagine" proper test cases for the coding question and filter the noisy ones. We sample inferences from existing coder models and compute their pass rate as the reliable and verifiable rewards for both training the reward model and conducting the reinforcement learning for coder LLM.
This model is the official AceCodeRM-7B trained from Qwen2.5-Coder-7B-Instruct on TIGER-Lab/AceCodePair-300K

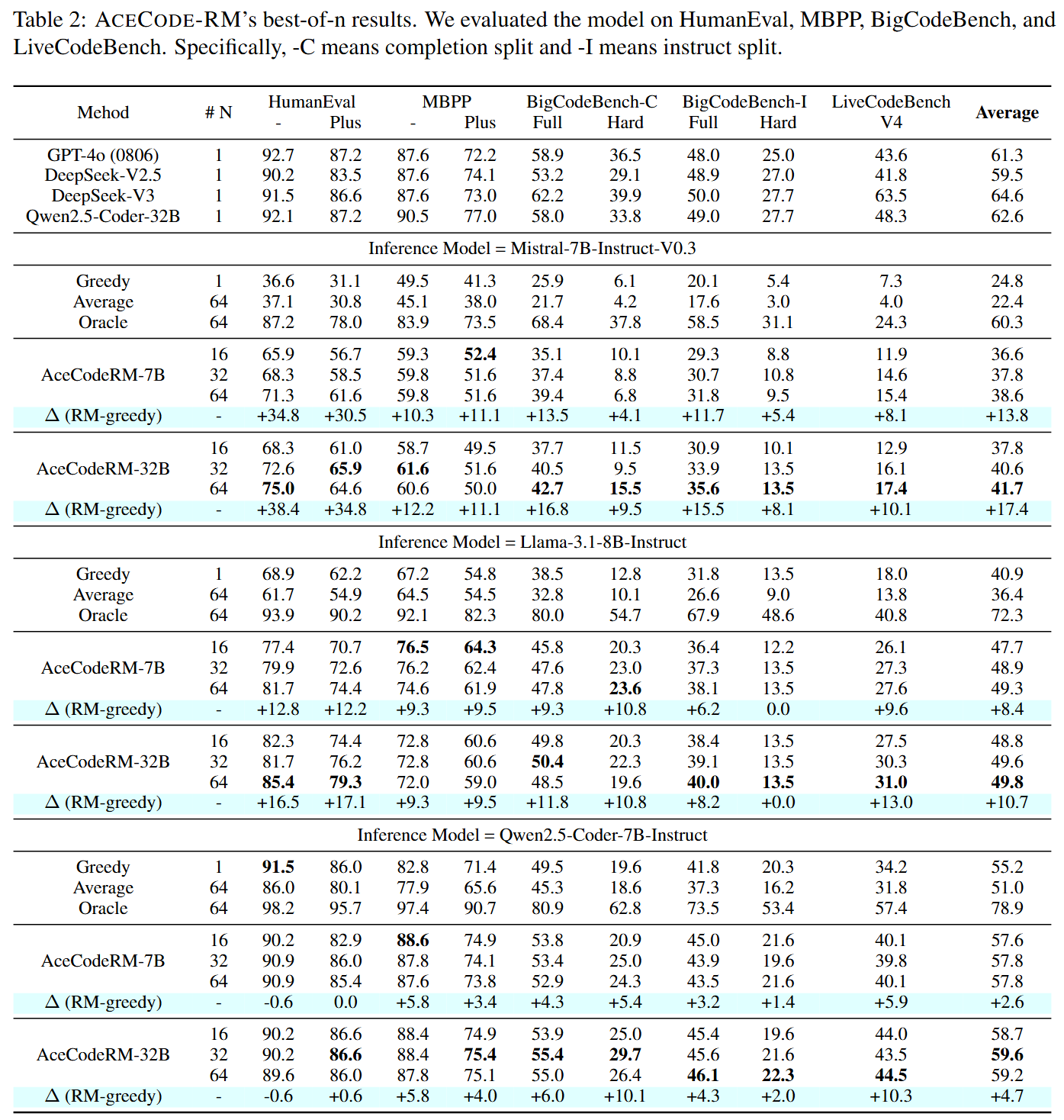
Performance on Best-of-N sampling
Usage
- To use the RM to produce rewards, please apply the following example codes:
import torch
import torch.nn as nn
from transformers import Qwen2ForCausalLM, AutoTokenizer
class ValueHead(nn.Module):
r"""
The ValueHead class implements a head for GPT2 that returns a scalar for each output token.
"""
def __init__(self, config, **kwargs):
super().__init__()
if not hasattr(config, "summary_dropout_prob"):
summary_dropout_prob = kwargs.pop("summary_dropout_prob", 0.1)
else:
summary_dropout_prob = config.summary_dropout_prob
self.dropout = (
nn.Dropout(summary_dropout_prob) if summary_dropout_prob else nn.Identity()
)
# some models such as OPT have a projection layer before the word embeddings - e.g. OPT-350m
if hasattr(config, "hidden_size"):
hidden_size = config.hidden_size
if hasattr(config, "word_embed_proj_dim"):
hidden_size = config.word_embed_proj_dim
elif hasattr(config, "is_encoder_decoder"):
if config.is_encoder_decoder and hasattr(config, "decoder"):
if hasattr(config.decoder, "hidden_size"):
hidden_size = config.decoder.hidden_size
self.summary = nn.Linear(hidden_size, 1)
self.flatten = nn.Flatten()
def forward(self, hidden_states):
output = self.dropout(hidden_states)
# For now force upcast in fp32 if needed. Let's keep the
# output in fp32 for numerical stability.
if output.dtype != self.summary.weight.dtype:
output = output.to(self.summary.weight.dtype)
output = self.summary(output)
return output
class Qwen2ForCausalRM(Qwen2ForCausalLM):
def __init__(self, config):
super().__init__(config)
self.v_head = ValueHead(config)
def forward(
self,
input_ids=None,
past_key_values=None,
attention_mask=None,
return_past_key_values=False,
**kwargs,
):
r"""
Applies a forward pass to the wrapped model and returns the logits of the value head.
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
past_key_values (`tuple(tuple(torch.FloatTensor))`, `optional`):
Contains pre-computed hidden-states (key and values in the attention blocks) as computed by the model
(see `past_key_values` input) to speed up sequential decoding.
attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
return_past_key_values (bool): A flag indicating if the computed hidden-states should be returned.
kwargs (`dict`, `optional`):
Additional keyword arguments, that are passed to the wrapped model.
"""
kwargs["output_hidden_states"] = (
True # this had already been set in the LORA / PEFT examples
)
kwargs["past_key_values"] = past_key_values
# if (
# self.is_peft_model
# and
# self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING"
# ):
# kwargs.pop("past_key_values")
base_model_output = super().forward(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs,
)
last_hidden_state = base_model_output.hidden_states[-1]
lm_logits = base_model_output.logits
loss = base_model_output.loss
if last_hidden_state.device != self.v_head.summary.weight.device:
last_hidden_state = last_hidden_state.to(self.v_head.summary.weight.device)
value = self.v_head(last_hidden_state).squeeze(-1)
# force upcast in fp32 if logits are in half-precision
if lm_logits.dtype != torch.float32:
lm_logits = lm_logits.float()
if return_past_key_values:
return (lm_logits, loss, value, base_model_output.past_key_values)
else:
return (lm_logits, loss, value)
model_path = "TIGER-Lab/AceCodeRM-7B"
model = Qwen2ForCausalRM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
input_chat = [
{"role": "user", "content": "Hello, how are you?"},
{
"role": "assistant",
"content": "I'm doing great. How can I help you today?",
},
{
"role": "user",
"content": "I'd like to show off how chat templating works!",
},
]
input_tokens = tokenizer.apply_chat_template(
input_chat,
tokenize=True,
return_dict=True,
padding=True,
return_tensors="pt",
).to(model.device)
_, _, values = model(
**input_tokens,
output_hidden_states=True,
return_dict=True,
use_cache=False,
)
masks = input_tokens["attention_mask"]
chosen_scores = values.gather(
dim=-1, index=(masks.sum(dim=-1, keepdim=True) - 1)
) # find the last token (eos) in each sequence, a
chosen_scores = chosen_scores.squeeze()
print(chosen_scores)
- To use the RM for the RL tuning, please refer to our Github Code for more details
Q&A
If you have any questions, please feel free to shoot us an email.