
TokSuite Model Collection
Collection
14 items
•
Updated
![]()
TokSuite–Gemma-2 is part of TokSuite, a suite of language models designed to study the impact of tokenizer choice on language model behavior under controlled conditions.
This model uses the Gemma-2 tokenizer and is otherwise identical to the other TokSuite models in architecture, training data, training budget, and initialization. The TokSuite setup ensures that any observed behavioral characteristics reflect properties of the tokenizer rather than differences in model scale, data composition, or optimization.
Processing details:
Gemma-2 was included in TokSuite to represent a large-vocabulary multilingual Unigram tokenizer trained with SentencePiece. As described in the tokenizer selection rationale of the TokSuite paper, Gemma-2 exemplifies a design point where probabilistic subword segmentation is paired with extensive vocabulary capacity.
Including Gemma-2 enables TokSuite to study tokenizer behavior in settings where:
This makes Gemma-2 a representative example of SentencePiece-based Unigram tokenization.
The architecture and training setup are identical across all TokSuite models; only the tokenizer differs.
The model was trained on a multilingual corpus totaling approximately 100B tokens, composed of:
You can find the pretraining dataset here: toksuite/toksuite_pretraining_data
All TokSuite models are trained using a fixed token budget, following standard practice in large-scale language model training.
The model was evaluated on standard base language model benchmarks:
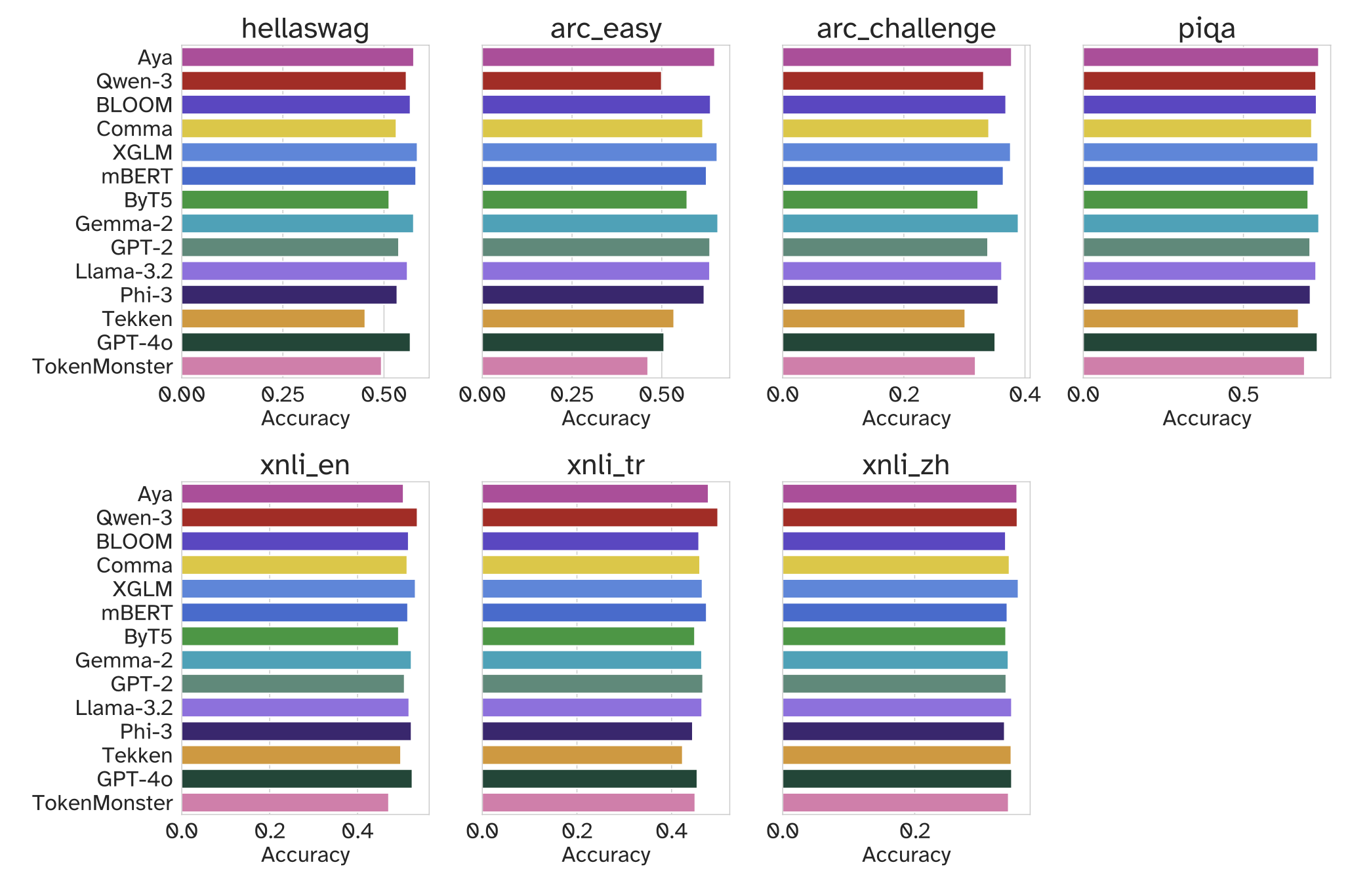
These evaluations verify that the model exhibits reasonable base language modeling behavior at its scale and training budget.
TokSuite–Gemma-2 is evaluated on the TokSuite robustness benchmark, which measures sensitivity to real-world text perturbations, including:
Tokenization Robustness under Multilingual Text Perturbations
Values represent relative performance drop, computed as (Acc_clean − Acc_perturbed) / Acc_clean, where lower values indicate greater robustness.
Perturbation types include:
NEN denotes non-English inputs and EN denotes English inputs. The Avg column reports the average relative performance drop across all perturbation categories.
| Model | Input (NEN) | Diacr. (NEN) | Orth. & Gram. (EN) | Orth. & Gram. (NEN) | Morph (EN) | Morph (NEN) | Noise (EN) | Noise (NEN) | LaTeX (EN) | STEM (EN) | Unic. (EN) | Avg ↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TokenMonster | 0.23 | 0.33 | 0.08 | 0.01 | 0.23 | -0.07 | 0.10 | 0.18 | 0.21 | 0.10 | 0.51 | 0.17 |
| XGLM | 0.34 | 0.49 | 0.10 | 0.11 | 0.25 | 0.07 | 0.12 | 0.22 | 0.29 | 0.29 | 0.11 | 0.22 |
| BLOOM | 0.30 | 0.34 | 0.13 | 0.07 | 0.18 | 0.11 | 0.18 | 0.18 | 0.24 | 0.11 | 0.57 | 0.22 |
| ByT5 | 0.30 | 0.44 | 0.04 | 0.06 | 0.27 | 0.04 | 0.14 | 0.18 | 0.17 | 0.29 | 0.53 | 0.22 |
| Comma | 0.28 | 0.43 | 0.05 | 0.07 | 0.18 | 0.00 | 0.11 | 0.20 | 0.23 | 0.29 | 0.61 | 0.22 |
| mBERT | 0.33 | 0.44 | 0.11 | 0.11 | 0.23 | 0.06 | 0.18 | 0.22 | 0.14 | 0.22 | 0.61 | 0.24 |
| GPT-4o | 0.30 | 0.51 | 0.08 | 0.05 | 0.21 | 0.05 | 0.16 | 0.19 | 0.24 | 0.33 | 0.55 | 0.24 |
| GPT-2 | 0.34 | 0.46 | 0.07 | 0.10 | 0.25 | 0.06 | 0.14 | 0.21 | 0.24 | 0.35 | 0.53 | 0.25 |
| Phi-3 | 0.33 | 0.46 | 0.16 | 0.09 | 0.27 | 0.08 | 0.17 | 0.21 | 0.24 | 0.22 | 0.55 | 0.25 |
| Gemma-2 | 0.32 | 0.42 | 0.14 | 0.15 | 0.24 | 0.03 | 0.16 | 0.25 | 0.22 | 0.36 | 0.57 | 0.26 |
| Qwen-3 | 0.36 | 0.42 | 0.14 | 0.11 | 0.25 | 0.06 | 0.16 | 0.23 | 0.26 | 0.29 | 0.57 | 0.26 |
| Llama-3.2 | 0.33 | 0.55 | 0.11 | 0.10 | 0.25 | 0.08 | 0.15 | 0.24 | 0.17 | 0.30 | 0.59 | 0.26 |
| Aya | 0.31 | 0.46 | 0.14 | 0.10 | 0.22 | 0.03 | 0.19 | 0.25 | 0.21 | 0.38 | 0.58 | 0.26 |
| Tekken | 0.33 | 0.47 | 0.18 | 0.03 | 0.31 | 0.10 | 0.14 | 0.21 | 0.27 | 0.43 | 0.54 | 0.27 |
| Avg | 0.31 | 0.44 | 0.11 | 0.08 | 0.24 | 0.04 | 0.15 | 0.21 | 0.22 | 0.28 | 0.53 | 0.24 |
This model is intended for:
It is not instruction-tuned, aligned, or optimized for deployment.
TokSuite models are released to support scientific investigation of tokenization effects.
They may reflect biases present in large-scale web data and should not be used in high-stakes or user-facing applications without additional safeguards.
If you use this model, please cite:
@article{toksuite2025,
title={TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior},
author={Altıntaş, Gul Sena and Ehghaghi, Malikeh and Lester, Brian and Liu, Fengyuan and Zhao, Wanru and Ciccone, Marco and Raffel, Colin},
year={2025},
arxiv={https://arxiv.org/abs/2512.20757},
}