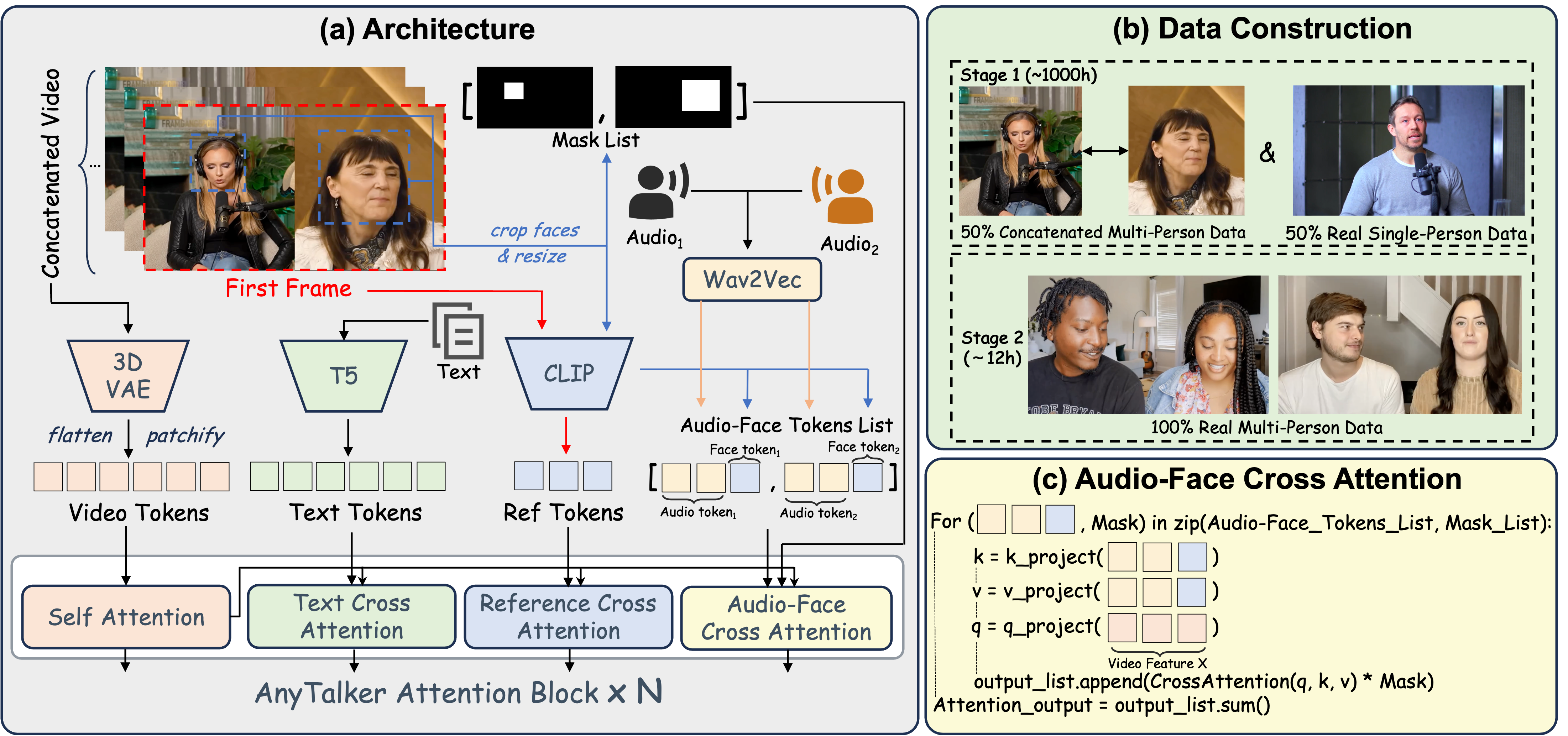
AnyTalker: Scaling Multi-Person Talking Video Generation with Interactivity Refinement
[Zhizhou Zhong](https://scholar.google.com/citations?user=t88nyvsAAAAJ ) · [Yicheng Ji](https://github.com/zju-jiyicheng) · [Zhe Kong](https://kongzhecn.github.io) · [Yiying Liu*](https://openreview.net/profile?id=~YiYing_Liu1) · [Jiarui Wang](https://scholar.google.com/citations?user=g7I2bJ8AAAAJ) · [Jiasun Feng](https://scholar.google.com/citations?hl=zh-CN&user=MGHcudEAAAAJ) · [Lupeng Liu](https://openreview.net/profile?id=~Lupeng_Liu2) · [Xiangyi Wang](https://openreview.net/profile?id=~Xiangyi_Wang6 ) · [Yanjia Li](https://openreview.net/profile?id=~Yanjia_Li1) · [Yuqing She](https://openreview.net/profile?id=~Yuqing_She1) · [Ying Qin](https://scholar.google.com/citations?user=6KwG7hYAAAAJ) · [Huan Li](https://scholar.google.com/citations?user=fZoYJz8AAAAJ ) · [Shuiyang Mao](https://scholar.google.com/citations?user=YZSd5fsAAAAJ) · [Wei Liu](https://scholar.google.com/citations?user=AjxoEpIAAAAJ) · [Wenhan Luo](https://whluo.github.io/)
✉
*Project Leader
✉Corresponding Author



> **TL; DR:** AnyTalker is an audio-driven framework for generating multi-person talking videos. It features a flexible multi-stream structure to scale identities while ensuring seamless inter-identity interactions.