

| Z-Image-Turbo-Fun-Controlnet-Union-2.1-8steps | Z-Image-Turbo-Fun-Controlnet-Union-2.1-2601-8steps |
|
|
| Z-Image-Turbo-Fun-Controlnet-Union-2.1-8steps | Z-Image-Turbo-Fun-Controlnet-Union-2.1-2601-8steps |
 |
 |
| Z-Image-Turbo-Fun-Controlnet-Union-2.1-8steps | Z-Image-Turbo-Fun-Controlnet-Union-2.1 |
 |
 |
| Pose | Output |
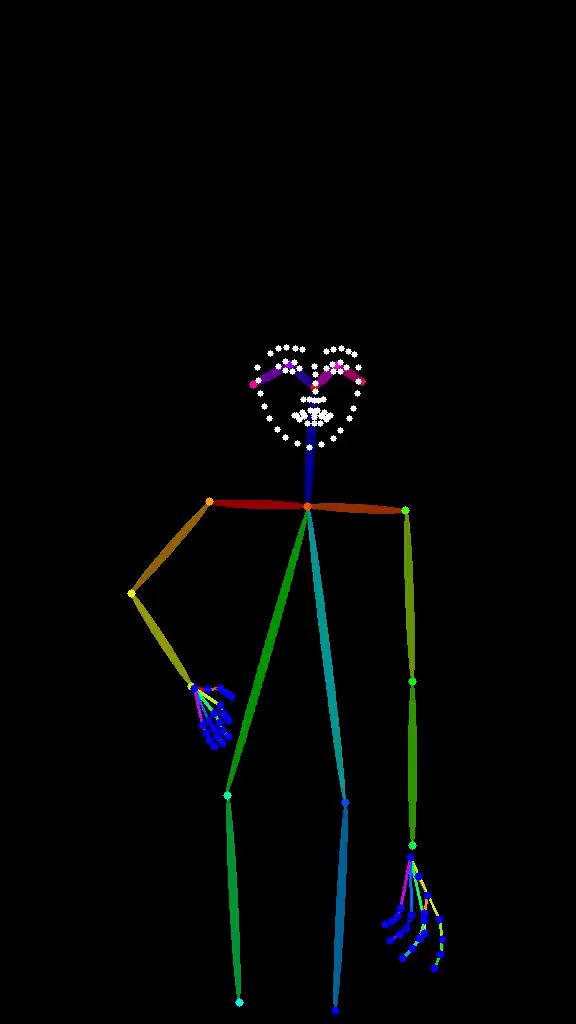 |
 |
| Pose | Output |
 |
 |
| Canny | Output |
 |
 |
| Depth | Output |
 |
 |
| Pose + Inpaint | Output |
  |
 |
| Pose + Inpaint | Output |
|
 |
| Pose | Output |
|
 |
| Pose | Output |
|
 |
| Pose | Output |
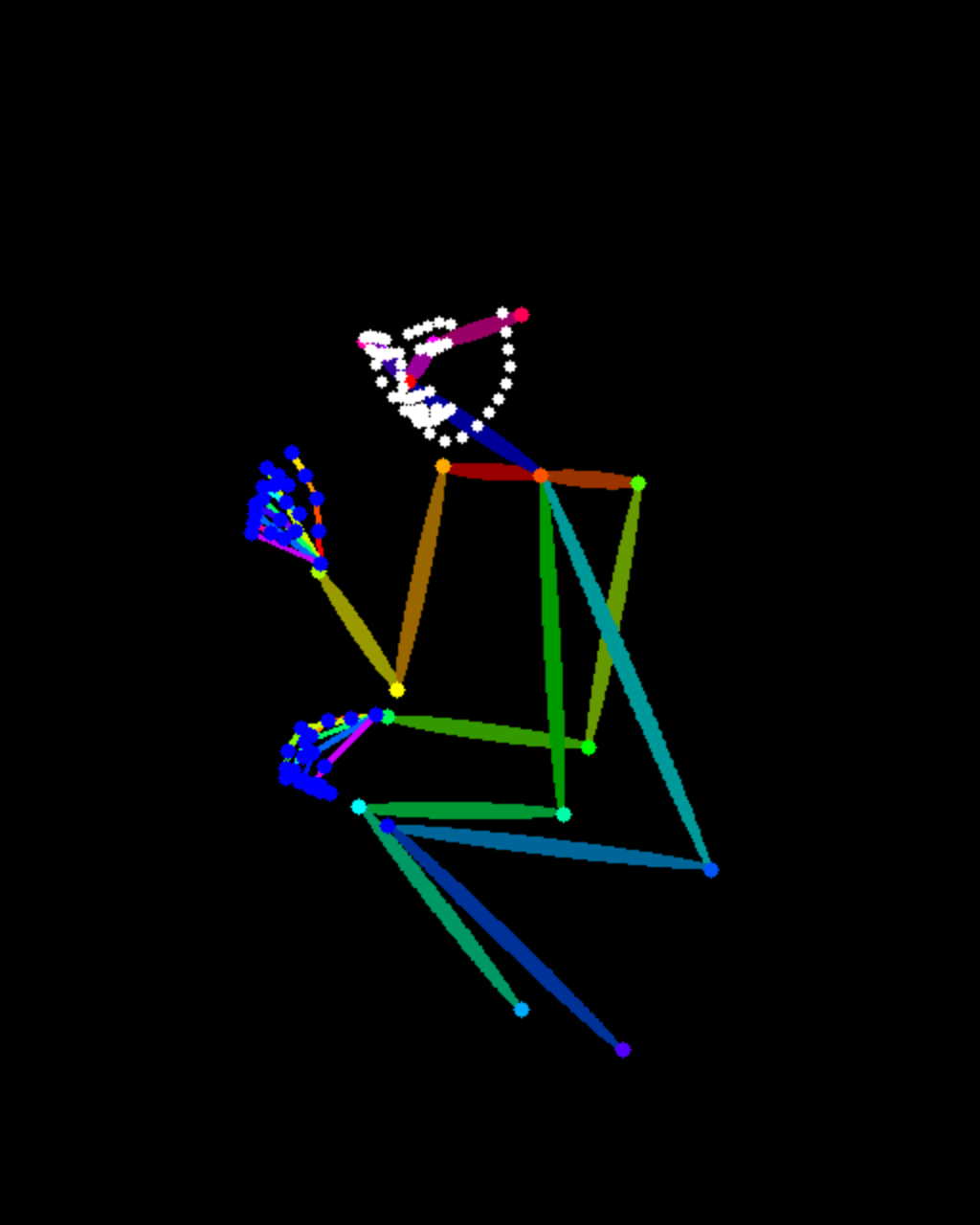 |
 |
| Canny | Output |
|
 |
| HED | Output |
 |
 |
| Depth | Output |
|
 |
| Low Resolution | High Resolution |
 |
 |
| Low Resolution | High Resolution |
 |
 |