---
language:
- en
- ja
- zh
license: cc-by-4.0
library_name: peft
base_model: Qwen/Qwen3-VL-8B-Instruct
tags:
- vision
- image-text-to-text
- qwen3
- qlora
- disaster-recognition
- xview2
- multi-lingual
- llama-factory
- visual-question-answering
- humanitarian-ai
datasets:
- WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA
pipeline_tag: image-text-to-text
---
# Qwen3VL-8B QLora 4-bit - xView2 Disaster Recognition
🌍 **Disaster Recognition Model** | 🚨 **Emergency Response** | 🗣️ **Trilingual (EN/JA/ZH)**
[](https://creativecommons.org/licenses/by/4.0/)
[](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct)
[](https://github.com/hiyouga/LLaMA-Factory)
[](https://huggingface.co/datasets/WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA)
**Built with Qwen3-VL** | **Fine-tuning**: 4-bit QLoRA | **Framework**: LLaMA-Factory | **Languages**: English, Japanese, Chinese
---
A multilingual vision-language model fine-tuned from [Qwen/Qwen3-VL-8B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct) for disaster type recognition using 4-bit QLoRA on the xView2 dataset.
## Model Description
This model specializes in identifying disaster types from satellite/aerial imagery. Through LoRA fine-tuning on 55,008 trilingual (English/Japanese/Chinese) disaster images, it learns to accurately classify various disaster types including fires, floods, hurricanes, earthquakes, tsunamis, and volcanic eruptions.
### Key Capabilities
- **🔥 Fire/Wildfire Recognition** - Identifies fire disasters from aerial imagery
- **🌊 Flood Detection** - Recognizes flooding disasters from satellite/aerial images
- **🌀 Hurricane/Wind Damage** - Detects wind disasters and hurricane impacts
- **🏚️ Earthquake Damage** - Identifies earthquake-affected areas
- **🌋 Volcanic Disasters** - Recognizes volcanic disaster patterns
- **🌊 Tsunami Impact** - Tsunami disaster identification
- **🗣️ Trilingual Support** - Responds accurately in English, Japanese, and Chinese
## Quick Start
### What is This Model?
This is a **LoRA adapter** (not a full model). You need to:
1. Load the base model: `Qwen/Qwen3-VL-8B-Instruct`
2. Apply this LoRA adapter on top of it
**Advantage**: Only ~22MB adapter download instead of ~8.7GB full model!
### Installation
```bash
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
```
### Usage
```python
from llamafactory.chat import ChatModel
# Initialize model with LoRA adapter
chat_model = ChatModel(args={
"model_name_or_path": "Qwen/Qwen3-VL-8B-Instruct",
"adapter_name_or_path": "WayBob/Qwen3VL-8B-QLora-4bit-xView2-Disaster-Recognition",
"template": "qwen3_vl_nothink",
"quantization_bit": 4,
"trust_remote_code": True,
"flash_attn": "fa2", # Optional: enable flash attention for faster inference
"infer_backend": "huggingface",
})
# Ask about disaster type in image
messages = [{"role": "user", "content": "\nWhat type of disaster occurred in this image?"}]
responses = chat_model.chat(messages=messages, images=["disaster_image.png"])
print(responses[0].response_text) # Output: "Fire disaster"
# Works in Japanese too
messages_ja = [{"role": "user", "content": "\nこの画像ではどのような種類の災害が発生しましたか?"}]
responses_ja = chat_model.chat(messages=messages_ja, images=["disaster_image.png"])
print(responses_ja[0].response_text) # Output: "火災災害"
# And Chinese
messages_zh = [{"role": "user", "content": "\n这张图片中发生了什么类型的灾害?"}]
responses_zh = chat_model.chat(messages=messages_zh, images=["disaster_image.png"])
print(responses_zh[0].response_text) # Output: "火灾"
```
### Hardware Requirements
| Configuration | VRAM Required |
|--------------|---------------|
| 4-bit Quantization (as used in training) | ~10-12GB |
| Inference only | ~8-10GB |
**Recommended GPU**: RTX 3090 / 4090 / A100 or equivalent with 12GB+ VRAM
## Training Details
### Base Model
- **Source**: [Qwen/Qwen3-VL-8B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct)
- **Parameters**: 8.7 billion
- **Architecture**: Qwen3-VL (Vision-Language)
- **Context Length**: 262,144 tokens
- **Vision Encoder**: ViT-based with spatial merge
### Training Data
**Dataset**: [WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA](https://huggingface.co/datasets/WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA)
This dataset is organized and prepared from the xView2 building damage assessment challenge, adapted for disaster type recognition tasks.
| Split | Samples | Languages | Coverage |
|-------|---------|-----------|----------|
| Training | 55,008 | EN/JA/ZH | All disaster types |
| Test | 5,598 | EN/JA/ZH | Held-out evaluation |
| **Total** | **60,606** | **Trilingual** | **Global disasters** |
**Disaster Types Covered**:
- 🔥 Fire/Wildfire
- 🌊 Flood
- 🌀 Hurricane/Wind damage
- 🏚️ Earthquake
- 🌊 Tsunami
- 🌋 Volcano
**Geographic Coverage**: Global dataset including disasters from North America, Asia, Europe, and other regions
**Data Format**: Post-disaster satellite/aerial imagery with corresponding disaster type annotations in three languages (English, Japanese, Chinese)
### Training Configuration
**Hardware**:
- **GPU**: NVIDIA RTX 4090 24GB
- **Framework**: [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory)
**Hyperparameters**:
```yaml
method: qlora_4bit
quantization: 4-bit (BitsAndBytes)
lora_rank: 8
lora_alpha: 16
lora_target: all (all linear layers)
lora_dropout: 0.05
learning_rate: 1.0e-4
batch_size: 4 per device × 2 accumulation = 8 effective
epochs: 3.0
optimizer: AdamW
lr_scheduler: cosine
warmup_ratio: 0.1
precision: bfloat16
image_max_pixels: 262144
```
**Training Duration**: ~6.4 hours (23,190 seconds)
**Memory Usage**: ~10-12GB VRAM
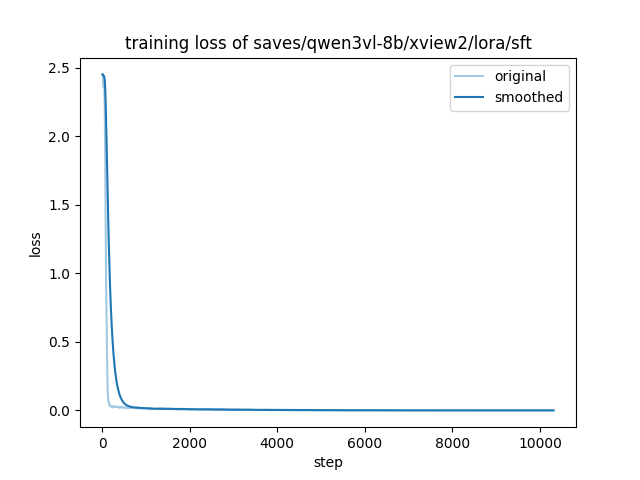
### Training Results
| Metric | Value |
|--------|-------|
| Final Training Loss | 0.0239 |
| Training Throughput | 7.12 samples/second |
| Total Training Steps | 10,314 |
| Training Duration | ~6.4 hours |
**Training Loss Curve:**
## Model Comparison Examples
Comparison between base model and fine-tuned model on disaster type recognition tasks. The following examples demonstrate significant improvements in accuracy and response quality.
#### Example 1: Fire Disaster (Southern California)
**Image**: `socal-fire_00001128_post_disaster.png`

**Question (English)**: "What type of disaster occurred in this image?"
| Model | Response |
|-------|----------|
| **Base Model** | "Based on the visual evidence in the image, this appears to be the aftermath of a **landslide or rockfall**... The debris at the bottom is the key indicator..."
❌ **INCORRECT** - Misidentified as landslide (acceptable?) |
| **Fine-tuned** | "Fire disaster"
✅ **CORRECT** - Accurate and concise |
| **Ground Truth** | "A fire disaster occurred in this image." |
---
#### Example 2: Flood Disaster (Hurricane Harvey)
**Image**: `hurricane-harvey_00000186_post_disaster.png`

**Question (English)**: "What type of disaster occurred in this image?"
| Model | Response |
|-------|----------|
| **Base Model** | "The image shows a **green algae bloom**, which is not a traditional disaster like a hurricane or earthquake, but it can be considered an **environmental disaster**..."
❌ **INCORRECT** - Completely misidentified |
| **Fine-tuned** | "Flood disaster"
✅ **CORRECT** |
| **Ground Truth** | "A flooding disaster occurred in this image." |
---
#### Example 3: Flood Disaster (Hurricane Florence)
**Image**: `hurricane-florence_00000145_post_disaster.png`

**Question (English)**: "What type of disaster occurred in this image?"
| Model | Response |
|-------|----------|
| **Base Model** | "Based on the image provided, there is no visible evidence of a disaster... The scene appears to be a normal, undisturbed landscape."
❌ **INCORRECT** - Failed to detect disaster |
| **Fine-tuned** | "Flooding"
✅ **CORRECT** |
| **Ground Truth** | "A flooding disaster occurred in this image." |
---
#### Example 4: Wind Disaster (Hurricane Michael) - Japanese
**Image**: `hurricane-michael_00000436_post_disaster.png`

**Question (Japanese)**: "この画像ではどのような種類の災害が発生しましたか?"
| Model | Response |
|-------|----------|
| **Base Model** | "この画像では**洪水**が発生したと推測されます..."
❌ **INCORRECT** - Misidentified as flood |
| **Fine-tuned** | "この画像では風災災害が発生しました。"
✅ **CORRECT** |
| **Ground Truth** | "この画像では風災災害が発生しました。" |
---
#### Example 5: Wind Disaster (Hurricane Michael) - Japanese
**Image**: `hurricane-michael_00000197_post_disaster.png`

**Question (Japanese)**: "この画像ではどのような種類の災害が発生しましたか?"
| Model | Response |
|-------|----------|
| **Base Model** | "この画像では**台風**による災害が発生しています。画像に見られるのは、台風の影響で甚大な被害を受けた都市部の衛星写真です..."
⚠️ **PARTIALLY CORRECT** - Correct but overly verbose (acceptable) |
| **Fine-tuned** | "この画像では風災災害が発生しました。"
✅ **CORRECT** - Accurate and concise |
| **Ground Truth** | "この画像では風災災害が発生しました。" |
### Key Improvements
The fine-tuned model demonstrates significant improvements over the base model:
- ✅ **Accurate Disaster Type Recognition** - Correctly identifies specific disaster types
- ✅ **Concise Responses** - Provides direct answers without unnecessary verbosity
- ✅ **Eliminated Hallucinations** - No longer invents non-existent disaster details
- ✅ **Consistent Multilingual Performance** - Reliable across English, Japanese, and Chinese
- ✅ **Reduced Misidentification** - Accurately distinguishes between different disaster types
## Use Cases
### Emergency Response & Humanitarian Aid
- **Rapid Damage Assessment**: Quickly identify disaster types from satellite imagery
- **Resource Allocation**: Prioritize aid based on disaster type recognition
- **Disaster Mapping**: Automatically tag disaster types in large image datasets
- **Multi-language Support**: Works with international teams (EN/JA/ZH)
### Research & Analysis
- **Disaster Dataset Annotation**: Accelerate labeling of disaster imagery
- **Historical Analysis**: Classify historical disaster images
- **Climate Impact Studies**: Track disaster type distributions over time
- **Cross-lingual Research**: Unified model for international collaborations
### Monitoring & Early Warning
- **Satellite Monitoring**: Automated disaster type identification from satellite feeds
- **Damage Verification**: Confirm disaster types reported by ground teams
- **Multi-source Intelligence**: Integrate with other disaster detection systems
## Training Reproduction
### Training Configuration File
```yaml
# examples/train_qlora/qwen3vl_8b_xview2_4bit.yaml
model_name_or_path: Qwen/Qwen3-VL-8B-Instruct
quantization_bit: 4
quantization_method: bnb
image_max_pixels: 262144
video_max_pixels: 16384
trust_remote_code: true
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 16
lora_target: all
lora_dropout: 0.05
dataset: xview2_disaster
eval_dataset: xview2_disaster_test
template: qwen3_vl_nothink
cutoff_len: 2048
max_samples: 55008
preprocessing_num_workers: 16
output_dir: saves/qwen3vl-8b/xview2/lora/sft
save_steps: 500
plot_loss: true
report_to: wandb
per_device_train_batch_size: 4
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
```
### Run Training
```bash
llamafactory-cli train examples/train_qlora/qwen3vl_8b_xview2_4bit.yaml
```
## Model Files
### Model Weights & Config
- `adapter_config.json` - LoRA adapter configuration
- `adapter_model.safetensors` - LoRA adapter weights (~22MB)
- `training_args.bin` - Training arguments
### Training Results
- `training_loss.png` - Training loss curve
- `trainer_log.jsonl` - Detailed training logs
- `all_results.json` - Final training metrics
- `train_results.json` - Training statistics
### Checkpoints
21 intermediate checkpoints saved every 500 steps:
- `checkpoint-500/` through `checkpoint-10000/`
- `checkpoint-10314/` (final checkpoint)
You can load any checkpoint by specifying its path in the `adapter_name_or_path` parameter.
## Limitations
- **Language**: Primarily trained on English/Japanese/Chinese; performance on other languages not guaranteed
- **Domain**: Specialized for post-disaster satellite/aerial imagery; may not work on ground-level photos
- **Disaster Type Coverage**: Some disaster types may have limited training samples, affecting recognition accuracy
- **Quantization**: Designed for 4-bit quantization; full precision inference not tested
- **Geographic Bias**: Training data may not cover all geographic regions equally
- **Model Evaluation**: Comprehensive evaluation is ongoing; performance metrics will be updated
## Intended Use Cases
**✅ Recommended**:
- Post-disaster satellite/aerial image analysis
- Disaster type classification for emergency response
- Automated disaster dataset annotation
- Multilingual disaster recognition (EN/JA/ZH)
- Research on disaster impact assessment
**❌ Not Recommended**:
- Real-time disaster prediction (this is classification, not prediction)
- Ground-level disaster assessment (trained on aerial imagery)
- Medical emergency classification
- Legal/insurance claim decisions without human verification
- Fine-grained damage severity assessment (binary disaster type only)
## Ethical Considerations
### Responsible Use
- **Human Oversight Required**: This model should augment, not replace, human disaster assessment
- **Verification Needed**: All classifications should be verified by disaster response professionals
- **Not for Sole Decision-Making**: Do not use as the only basis for resource allocation or policy decisions
- **Privacy**: Be mindful of privacy when processing imagery that may contain identifiable information
- **Bias Awareness**: Model performance may vary across geographic regions and disaster contexts
### Humanitarian Applications
This model is intended to support humanitarian efforts and disaster response. We encourage:
- Open collaboration with disaster response organizations
- Responsible sharing of insights with affected communities
- Transparent communication of model limitations
- Continuous improvement based on real-world feedback
## Citation
```bibtex
@misc{qwen3vl-8b-qlora-xview2-disaster,
author = {WayBob},
title = {Qwen3VL-8B QLora 4-bit xView2 Disaster Recognition},
year = {2025},
publisher = {HuggingFace},
url = {https://huggingface.co/WayBob/Qwen3VL-8B-QLora-4bit-xView2-Disaster-Recognition}
}
@misc{disaster-recognition-dataset,
title={Disaster Recognition RemoteSense Dataset (EN/CN/JA)},
author={WayBob},
year={2025},
publisher={HuggingFace},
url={https://huggingface.co/datasets/WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA}
}
@inproceedings{xview2,
title={xBD: A Dataset for Assessing Building Damage from Satellite Imagery},
author={Gupta, Ritwik and Hosfelt, Richard and Sajeev, Sandra and Patel, Nirav and Goodman, Bryce and Doshi, Jigar and Heim, Eric and Choset, Howie and Gaston, Matthew},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
year={2019}
}
```
## Acknowledgements
**Base Model**:
- [Qwen3-VL-8B-Instruct](https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct) - Alibaba Cloud Qwen Team
- Licensed under Apache 2.0
**Dataset**:
- [WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA](https://huggingface.co/datasets/WayBob/Disaster_Recognition_RemoteSense_EN_CN_JA) - Trilingual disaster recognition dataset
- Organized and prepared from xView2 building damage assessment challenge
- Original xView2 dataset by DIUx (Defense Innovation Unit)
- Licensed under Creative Commons
**Training Framework**:
- [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) by hiyouga
**Method**:
- [QLoRA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/abs/2305.14314) by Dettmers et al.
**Infrastructure**:
- NVIDIA RTX 4090 24GB GPU
## License
This model is licensed under **Creative Commons Attribution 4.0 International (CC-BY-4.0)**.
### Key License Terms
- **Share**: You can copy and redistribute the material in any medium or format for any purpose, even commercially
- **Adapt**: You can remix, transform, and build upon the material for any purpose, even commercially
- **Attribution**: You must give appropriate credit, provide a link to the license, and indicate if changes were made
- **No Additional Restrictions**: You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits
**Full License**: See [CC-BY-4.0 License](https://creativecommons.org/licenses/by/4.0/) for complete terms.
## Contact
- HuggingFace: [WayBob](https://huggingface.co/WayBob)
- Model Repository: [Qwen3VL-8B-QLora-4bit-xView2-Disaster-Recognition](https://huggingface.co/WayBob/Qwen3VL-8B-QLora-4bit-xView2-Disaster-Recognition)
- Issues: Please report issues or suggestions through HuggingFace discussions
---
**Disclaimer**: This model is provided for research and humanitarian purposes. Always verify model outputs with domain experts before making critical decisions based on disaster classifications.