
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,9 +7,93 @@ datasets:
|
|
| 7 |
language:
|
| 8 |
- ru
|
| 9 |
- en
|
| 10 |
-
base_model:
|
| 11 |
-
|
| 12 |
-
pipeline_tag: text-generation
|
| 13 |
-
tags:
|
| 14 |
-
- mlx
|
| 15 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
language:
|
| 8 |
- ru
|
| 9 |
- en
|
| 10 |
+
base_model:
|
| 11 |
+
- Qwen/Qwen3-4B
|
|
|
|
|
|
|
|
|
|
| 12 |
---
|
| 13 |
+
<p align="left">
|
| 14 |
+
<a href="https://jle.hse.ru/article/view/22224"><b>Paper Link</b>👁️</a>
|
| 15 |
+
<br>
|
| 16 |
+
<a href="https://huggingface.co/RefalMachine/RuadaptQwen3-4B-Instruct-GGUF"><b>GGUF</b>🚀</a>
|
| 17 |
+
</p>
|
| 18 |
+
<hr>
|
| 19 |
+
|
| 20 |
+
# RU
|
| 21 |
+
## Описание модели
|
| 22 |
+
|
| 23 |
+
**Ruadapt** версия модели **Qwen/Qwen3-4B**. В модели был заменен токенизатор, затем произведено дообучение (Continued pretraining) на русскоязычном корпусе, после чего была применена техника **LEP (Learned Embedding Propagation)**.
|
| 24 |
+
|
| 25 |
+
Благодаря новому токенизатору (расширенный tiktoken cl100k с помощью униграм токенизатора на 48 т. токенов) скорость генерации* русскоязычных текстов возрасла **до 100%** (в зависимости от длины контекста) по сравнению с исходной моделью.
|
| 26 |
+
|
| 27 |
+
**Под скоростью генерации подразумевается количество русскоязычных символов/слов в секунду на одинаковых текстовых последовательностях.*
|
| 28 |
+
|
| 29 |
+
## Важно
|
| 30 |
+
|
| 31 |
+
**Веса модели могут обновляться** по мере получения новых версий. Информацию о версиях будет в самом конце README, там же фиксируются **даты** и **коммиты** версий, чтобы всегда можно было использовать предыдущие варианты при необходимости.
|
| 32 |
+
|
| 33 |
+
Ответы модели не отражают мнения авторов, а лишь повторяют знания полученные из данных на всех этапах обучения (предобучение, смена токенизатора, обучение на инструкциях, калибровка качества ответов). Модель была получена из сторонней предобученной модели, **контроль за предобучением** которой **не является ответственностью текущих авторов**. При создании данной версии модели не производилось никаких дополнительных действий, направленных на изменение заложенных в LLM "мнений". Используйте с осторожностью.
|
| 34 |
+
|
| 35 |
+
## Гибридрый ризонер
|
| 36 |
+
|
| 37 |
+
Модель, как и ее исходная версия, является гибридным ризонером. По умолчанию модель работает с включенным режимом размышлений.
|
| 38 |
+
Чтобы отключить режим рассуждений, добавьте в конец последнего сообщения токен /no_think.
|
| 39 |
+
Чтобы обратно его включить, добавьте /think.
|
| 40 |
+
|
| 41 |
+
Альтернативный способ при работе с моделью напрямую:
|
| 42 |
+
```python
|
| 43 |
+
text = tokenizer.apply_chat_template(
|
| 44 |
+
messages,
|
| 45 |
+
tokenize=False,
|
| 46 |
+
add_generation_prompt=True,
|
| 47 |
+
enable_thinking=False # Setting enable_thinking=False disables thinking mode
|
| 48 |
+
)
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
## Рекомендуемые параметры генерации
|
| 52 |
+
Для более стабильной работы рекомендуется использовать низкие температуры 0.0-0.3, top_p в диапазоне от 0.85 до 0.95 и repetition_penalty 1.05 (зависит от задач, но если уходит в циклы, то пробуйте поднять repetition_penalty. В случае же RAG, возможно наоборот снизить до 1.0).
|
| 53 |
+
|
| 54 |
+
## Метрики
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
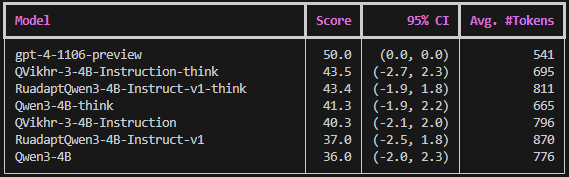
|
| 58 |
+
|
| 59 |
+
*Рейтинг на считался на Vikhrmodels/arenahardlb с использованием DeepSeek-V3-0324 в качестве оценщика против модели gpt-4-1106-preview с включенным length-control.
|
| 60 |
+
|
| 61 |
+

|
| 62 |
+
|
| 63 |
+
*Метрики на DOoM ведут себя несколько нестабильно и существенно зависят от параметров сэмплирования. Метрика на Rubabilong считалась для части датасета (по 200 примеров с каждого из 5 датасетов).
|
| 64 |
+
# EN
|
| 65 |
+
|
| 66 |
+
## Model Description
|
| 67 |
+
|
| 68 |
+
**Ruadapt** version of **Qwen/Qwen3-4B**.
|
| 69 |
+
In this model the tokenizer was replaced, followed by continued pre-training on a Russian-language corpus, after which the **LEP (Learned Embedding Propagation)** technique was applied.
|
| 70 |
+
|
| 71 |
+
Thanks to the new tokenizer (an extended tiktoken cl100k, augmented with a 48 k russian tokens), the generation speed* of Russian-language texts has increased **by up to 100 %** (depending on context length) compared with the original model.
|
| 72 |
+
|
| 73 |
+
*Generation speed is understood as the number of Russian characters/words produced per second on identical text sequences.*
|
| 74 |
+
## Important
|
| 75 |
+
|
| 76 |
+
The model may be updated as new versions become available. Version information is provided at the very end of the README, where **dates** and **commits** are logged so that previous versions can always be used if necessary.
|
| 77 |
+
|
| 78 |
+
The model’s answers do not reflect the authors’ opinions; they merely reproduce the knowledge obtained from data at all training stages (pre-training, tokenizer replacement, instruction tuning, answer-quality calibration). The model is based on a third-party pretrained model, and **the current authors are not responsible for its initial pre-training**. No additional actions were taken to modify the “opinions” embedded in the LLM while creating this version. Use with caution.
|
| 79 |
+
|
| 80 |
+
<hr>
|
| 81 |
+
|
| 82 |
+
# Other
|
| 83 |
+
|
| 84 |
+
## Tokenization
|
| 85 |
+
|
| 86 |
+

|
| 87 |
+
|
| 88 |
+

|
| 89 |
+
|
| 90 |
+
## Versions
|
| 91 |
+
|
| 92 |
+
v1:
|
| 93 |
+
- [fee9e76d8fbaa04b59793d0e9d9362faa8a496c9](https://huggingface.co/RefalMachine/RuadaptQwen3-4B-Instruct/commit/fee9e76d8fbaa04b59793d0e9d9362faa8a496c9)
|
| 94 |
+
- Внутреннее имя/Alias: RuadaptQwen3-4B-Instruct-v1
|
| 95 |
+
- Дата/Date: 30.06.2025
|
| 96 |
+
|
| 97 |
+
## How to cite:
|
| 98 |
+
|
| 99 |
+
Tikhomirov M., Chernyshov D. Facilitating Large Language Model Russian Adaptation with Learned Embedding Propagation //Journal of Language and Education. – 2024. – Т. 10. – №. 4. – С. 130-145.
|