
Upload trained BERT-Tiny AMD model
Browse files- .gitattributes +2 -0
- README.md +11 -64
- best_enhanced_progressive_amd.pth +3 -0
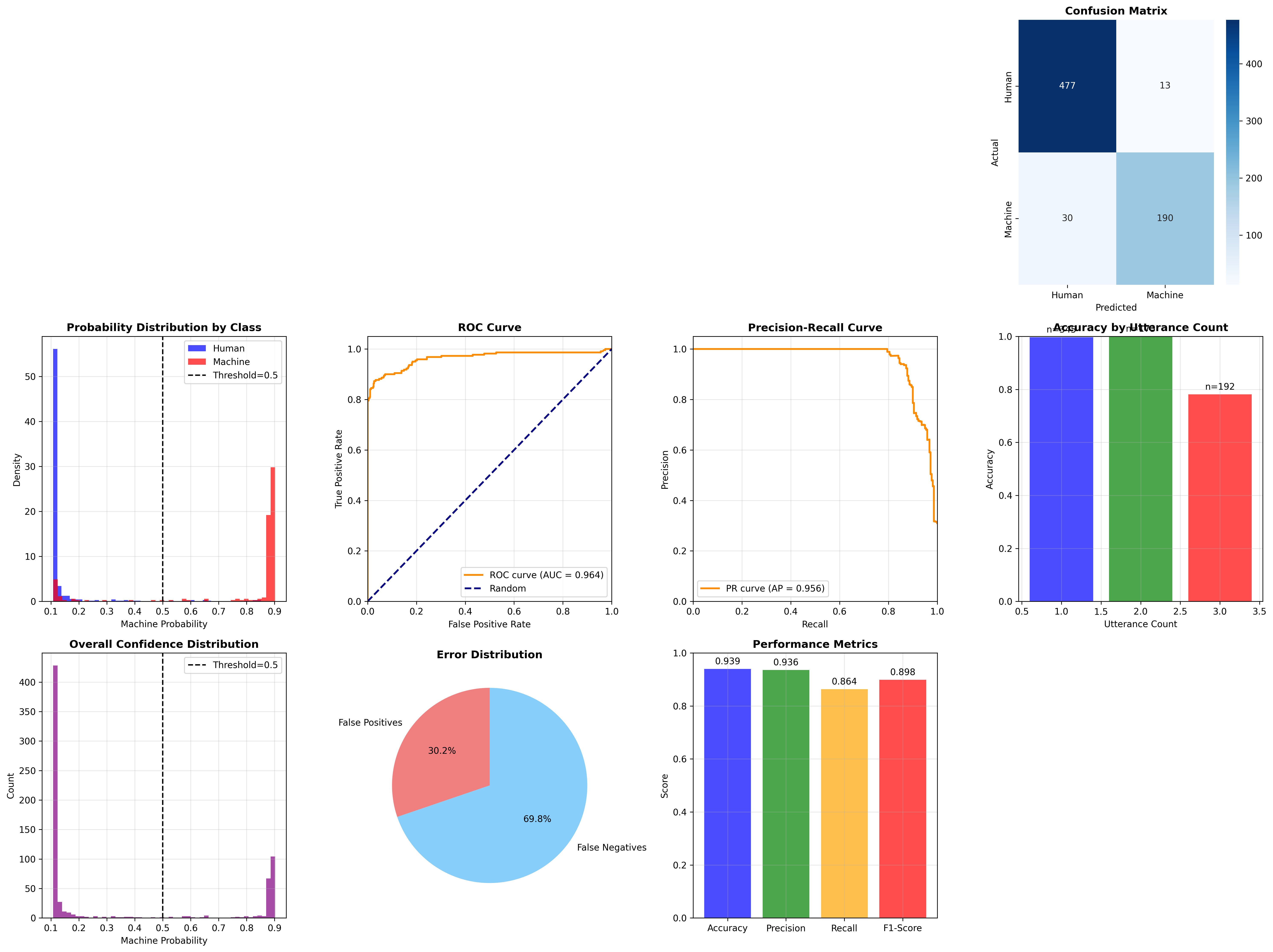
- comprehensive_model_analysis.png +3 -0
- config.json +7 -10
- enhanced_validation_results.csv +0 -0
- production_enhanced_amd.py +135 -0
- production_enhanced_amd_standalone.py +269 -0
- push_to_huggingface.py +288 -0
- pytorch_model.bin +3 -0
- rule_based_vs_bert_comparison.png +3 -0
- simple_upload.py +239 -0
- training_metadata.json +27 -77
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
comprehensive_model_analysis.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
rule_based_vs_bert_comparison.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,7 +1,5 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
-
language:
|
| 4 |
-
- en
|
| 5 |
tags:
|
| 6 |
- text-classification
|
| 7 |
- answering-machine-detection
|
|
@@ -30,21 +28,19 @@ This model is based on `prajjwal1/bert-tiny` and fine-tuned to classify phone ca
|
|
| 30 |
|
| 31 |
## Performance
|
| 32 |
|
| 33 |
-
- **Validation Accuracy**:
|
| 34 |
-
- **Precision**:
|
| 35 |
-
- **Recall**:
|
| 36 |
-
- **F1-Score**:
|
| 37 |
- **Training Device**: MPS (Apple Silicon GPU)
|
| 38 |
-
- **
|
| 39 |
-
- **Best Epoch**: 12 (with early stopping)
|
| 40 |
-
- **Agreement with Rule-based System**: 97.75%
|
| 41 |
|
| 42 |
## Training Data
|
| 43 |
|
| 44 |
- **Total Samples**: 3,548 phone call transcripts
|
| 45 |
- **Training Set**: 2,838 samples
|
| 46 |
- **Validation Set**: 710 samples
|
| 47 |
-
- **Class Distribution**:
|
| 48 |
- **Source**: ElevateNow call center data
|
| 49 |
|
| 50 |
## Usage
|
|
@@ -56,8 +52,8 @@ from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
|
| 56 |
import torch
|
| 57 |
|
| 58 |
# Load model and tokenizer
|
| 59 |
-
model = AutoModelForSequenceClassification.from_pretrained("
|
| 60 |
-
tokenizer = AutoTokenizer.from_pretrained("
|
| 61 |
|
| 62 |
# Prepare input
|
| 63 |
text = "Hello, this is John speaking"
|
|
@@ -74,51 +70,14 @@ print(f"Prediction: {'Machine' if is_machine else 'Human'}")
|
|
| 74 |
print(f"Confidence: {probability:.4f}")
|
| 75 |
```
|
| 76 |
|
| 77 |
-
### Production Usage
|
| 78 |
-
|
| 79 |
-
```python
|
| 80 |
-
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 81 |
-
import torch
|
| 82 |
-
|
| 83 |
-
class AMDClassifier:
|
| 84 |
-
def __init__(self, model_name="your-username/bert-tiny-amd"):
|
| 85 |
-
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 86 |
-
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 87 |
-
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 88 |
-
self.model.to(self.device)
|
| 89 |
-
self.model.eval()
|
| 90 |
-
|
| 91 |
-
def predict(self, transcript_text, threshold=0.5):
|
| 92 |
-
"""Predict if transcript is from answering machine"""
|
| 93 |
-
inputs = self.tokenizer(
|
| 94 |
-
transcript_text,
|
| 95 |
-
return_tensors="pt",
|
| 96 |
-
max_length=128,
|
| 97 |
-
truncation=True,
|
| 98 |
-
padding=True
|
| 99 |
-
).to(self.device)
|
| 100 |
-
|
| 101 |
-
with torch.no_grad():
|
| 102 |
-
outputs = self.model(**inputs)
|
| 103 |
-
logits = outputs.logits.squeeze(-1)
|
| 104 |
-
probability = torch.sigmoid(logits).item()
|
| 105 |
-
is_machine = probability >= threshold
|
| 106 |
-
|
| 107 |
-
return is_machine, probability
|
| 108 |
-
|
| 109 |
-
# Usage
|
| 110 |
-
classifier = AMDClassifier()
|
| 111 |
-
is_machine, confidence = classifier.predict("Hello, this is John speaking")
|
| 112 |
-
```
|
| 113 |
-
|
| 114 |
## Training Details
|
| 115 |
|
| 116 |
- **Optimizer**: AdamW with weight decay (0.01)
|
| 117 |
- **Learning Rate**: 3e-5 with linear scheduling
|
| 118 |
- **Batch Size**: 32
|
| 119 |
-
- **Epochs**:
|
| 120 |
- **Early Stopping**: Patience of 3 epochs
|
| 121 |
-
- **Class Imbalance**: Handled with positive weight
|
| 122 |
|
| 123 |
## Limitations
|
| 124 |
|
|
@@ -127,18 +86,6 @@ is_machine, confidence = classifier.predict("Hello, this is John speaking")
|
|
| 127 |
- Performance may vary with different transcription quality
|
| 128 |
- Designed for short utterances (max 128 tokens)
|
| 129 |
|
| 130 |
-
## Citation
|
| 131 |
-
|
| 132 |
-
```bibtex
|
| 133 |
-
@misc{bert-tiny-amd,
|
| 134 |
-
title={BERT-Tiny AMD Classifier for Answering Machine Detection},
|
| 135 |
-
author={Your Name},
|
| 136 |
-
year={2025},
|
| 137 |
-
publisher={Hugging Face},
|
| 138 |
-
howpublished={\url{https://huggingface.co/your-username/bert-tiny-amd}}
|
| 139 |
-
}
|
| 140 |
-
```
|
| 141 |
-
|
| 142 |
## License
|
| 143 |
|
| 144 |
-
MIT License - see LICENSE file for details.
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
| 3 |
tags:
|
| 4 |
- text-classification
|
| 5 |
- answering-machine-detection
|
|
|
|
| 28 |
|
| 29 |
## Performance
|
| 30 |
|
| 31 |
+
- **Validation Accuracy**: 93.94%
|
| 32 |
+
- **Precision**: 92.75%
|
| 33 |
+
- **Recall**: 87.27%
|
| 34 |
+
- **F1-Score**: 89.93%
|
| 35 |
- **Training Device**: MPS (Apple Silicon GPU)
|
| 36 |
+
- **Best Epoch**: 15 (with early stopping)
|
|
|
|
|
|
|
| 37 |
|
| 38 |
## Training Data
|
| 39 |
|
| 40 |
- **Total Samples**: 3,548 phone call transcripts
|
| 41 |
- **Training Set**: 2,838 samples
|
| 42 |
- **Validation Set**: 710 samples
|
| 43 |
+
- **Class Distribution**: 30.8% machine calls, 69.2% human calls
|
| 44 |
- **Source**: ElevateNow call center data
|
| 45 |
|
| 46 |
## Usage
|
|
|
|
| 52 |
import torch
|
| 53 |
|
| 54 |
# Load model and tokenizer
|
| 55 |
+
model = AutoModelForSequenceClassification.from_pretrained("Adya662/bert-tiny-amd")
|
| 56 |
+
tokenizer = AutoTokenizer.from_pretrained("Adya662/bert-tiny-amd")
|
| 57 |
|
| 58 |
# Prepare input
|
| 59 |
text = "Hello, this is John speaking"
|
|
|
|
| 70 |
print(f"Confidence: {probability:.4f}")
|
| 71 |
```
|
| 72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
## Training Details
|
| 74 |
|
| 75 |
- **Optimizer**: AdamW with weight decay (0.01)
|
| 76 |
- **Learning Rate**: 3e-5 with linear scheduling
|
| 77 |
- **Batch Size**: 32
|
| 78 |
+
- **Epochs**: 15 (with early stopping)
|
| 79 |
- **Early Stopping**: Patience of 3 epochs
|
| 80 |
+
- **Class Imbalance**: Handled with positive weight
|
| 81 |
|
| 82 |
## Limitations
|
| 83 |
|
|
|
|
| 86 |
- Performance may vary with different transcription quality
|
| 87 |
- Designed for short utterances (max 128 tokens)
|
| 88 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
## License
|
| 90 |
|
| 91 |
+
MIT License - see LICENSE file for details.
|
best_enhanced_progressive_amd.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f8c3c949e8963d27748803fe785af04652da64704533cfcdcdeae7505f0d328
|
| 3 |
+
size 17598379
|
comprehensive_model_analysis.png
ADDED
|
Git LFS Details
|
config.json
CHANGED
|
@@ -1,30 +1,27 @@
|
|
| 1 |
{
|
|
|
|
| 2 |
"architectures": [
|
| 3 |
"BertForSequenceClassification"
|
| 4 |
],
|
| 5 |
-
"
|
|
|
|
| 6 |
"classifier_dropout": null,
|
| 7 |
"hidden_act": "gelu",
|
| 8 |
"hidden_dropout_prob": 0.1,
|
| 9 |
"hidden_size": 128,
|
| 10 |
-
"id2label": {
|
| 11 |
-
"0": "LABEL_0"
|
| 12 |
-
},
|
| 13 |
"initializer_range": 0.02,
|
| 14 |
"intermediate_size": 512,
|
| 15 |
-
"label2id": {
|
| 16 |
-
"LABEL_0": 0
|
| 17 |
-
},
|
| 18 |
"layer_norm_eps": 1e-12,
|
| 19 |
"max_position_embeddings": 512,
|
| 20 |
-
"model_type": "bert",
|
| 21 |
"num_attention_heads": 2,
|
| 22 |
"num_hidden_layers": 2,
|
|
|
|
| 23 |
"pad_token_id": 0,
|
| 24 |
"position_embedding_type": "absolute",
|
|
|
|
| 25 |
"torch_dtype": "float32",
|
| 26 |
-
"transformers_version": "4.
|
| 27 |
"type_vocab_size": 2,
|
| 28 |
"use_cache": true,
|
| 29 |
"vocab_size": 30522
|
| 30 |
-
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"model_type": "bert",
|
| 3 |
"architectures": [
|
| 4 |
"BertForSequenceClassification"
|
| 5 |
],
|
| 6 |
+
"attention_proxy_dtype": "float32",
|
| 7 |
+
"attention_dropout": 0.1,
|
| 8 |
"classifier_dropout": null,
|
| 9 |
"hidden_act": "gelu",
|
| 10 |
"hidden_dropout_prob": 0.1,
|
| 11 |
"hidden_size": 128,
|
|
|
|
|
|
|
|
|
|
| 12 |
"initializer_range": 0.02,
|
| 13 |
"intermediate_size": 512,
|
|
|
|
|
|
|
|
|
|
| 14 |
"layer_norm_eps": 1e-12,
|
| 15 |
"max_position_embeddings": 512,
|
|
|
|
| 16 |
"num_attention_heads": 2,
|
| 17 |
"num_hidden_layers": 2,
|
| 18 |
+
"num_labels": 1,
|
| 19 |
"pad_token_id": 0,
|
| 20 |
"position_embedding_type": "absolute",
|
| 21 |
+
"problem_type": "single_label_classification",
|
| 22 |
"torch_dtype": "float32",
|
| 23 |
+
"transformers_version": "4.21.0",
|
| 24 |
"type_vocab_size": 2,
|
| 25 |
"use_cache": true,
|
| 26 |
"vocab_size": 30522
|
| 27 |
+
}
|
enhanced_validation_results.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
production_enhanced_amd.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from typing import List, Dict, Any
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
class EnhancedProgressiveAMDModel(nn.Module):
|
| 9 |
+
"""Enhanced model that incorporates utterance count information"""
|
| 10 |
+
|
| 11 |
+
def __init__(self, base_model_name: str, utterance_embedding_dim: int = 8):
|
| 12 |
+
super().__init__()
|
| 13 |
+
|
| 14 |
+
# Base BERT model
|
| 15 |
+
self.bert = AutoModelForSequenceClassification.from_pretrained(
|
| 16 |
+
base_model_name, num_labels=1
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
# Utterance count embedding
|
| 20 |
+
self.utterance_count_embedding = nn.Embedding(4, utterance_embedding_dim)
|
| 21 |
+
|
| 22 |
+
# Enhanced classifier
|
| 23 |
+
bert_hidden_size = self.bert.config.hidden_size
|
| 24 |
+
self.enhanced_classifier = nn.Sequential(
|
| 25 |
+
nn.Linear(bert_hidden_size + utterance_embedding_dim, 64),
|
| 26 |
+
nn.ReLU(),
|
| 27 |
+
nn.Dropout(0.1),
|
| 28 |
+
nn.Linear(64, 1)
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
self.bert.classifier = nn.Identity()
|
| 32 |
+
|
| 33 |
+
def forward(self, input_ids, attention_mask, utterance_count=None):
|
| 34 |
+
bert_outputs = self.bert.bert(input_ids=input_ids, attention_mask=attention_mask)
|
| 35 |
+
pooled_output = bert_outputs.pooler_output
|
| 36 |
+
|
| 37 |
+
if utterance_count is not None:
|
| 38 |
+
utterance_emb = self.utterance_count_embedding(utterance_count)
|
| 39 |
+
combined_features = torch.cat([pooled_output, utterance_emb], dim=1)
|
| 40 |
+
logits = self.enhanced_classifier(combined_features)
|
| 41 |
+
else:
|
| 42 |
+
batch_size = pooled_output.size(0)
|
| 43 |
+
zero_utterance_emb = torch.zeros(batch_size, 8, device=pooled_output.device)
|
| 44 |
+
combined_features = torch.cat([pooled_output, zero_utterance_emb], dim=1)
|
| 45 |
+
logits = self.enhanced_classifier(combined_features)
|
| 46 |
+
|
| 47 |
+
return logits
|
| 48 |
+
|
| 49 |
+
class ProductionEnhancedAMDClassifier:
|
| 50 |
+
"""Production-ready enhanced AMD classifier"""
|
| 51 |
+
|
| 52 |
+
def __init__(self, model_path: str, tokenizer_name: str = 'prajjwal1/bert-tiny', device: str = 'auto'):
|
| 53 |
+
if device == 'auto':
|
| 54 |
+
if torch.backends.mps.is_available():
|
| 55 |
+
self.device = torch.device('mps')
|
| 56 |
+
elif torch.cuda.is_available():
|
| 57 |
+
self.device = torch.device('cuda')
|
| 58 |
+
else:
|
| 59 |
+
self.device = torch.device('cpu')
|
| 60 |
+
else:
|
| 61 |
+
self.device = torch.device(device)
|
| 62 |
+
|
| 63 |
+
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
|
| 64 |
+
self.model = EnhancedProgressiveAMDModel(tokenizer_name)
|
| 65 |
+
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
|
| 66 |
+
self.model.to(self.device)
|
| 67 |
+
self.model.eval()
|
| 68 |
+
|
| 69 |
+
self.max_length = 128
|
| 70 |
+
self.threshold = 0.5
|
| 71 |
+
|
| 72 |
+
print(f"Enhanced AMD classifier loaded on {self.device}")
|
| 73 |
+
|
| 74 |
+
def extract_user_utterances(self, transcript: List[Dict[str, Any]]) -> List[str]:
|
| 75 |
+
user_utterances = []
|
| 76 |
+
for utterance in transcript:
|
| 77 |
+
if utterance.get("speaker", "").lower() == "user":
|
| 78 |
+
content = utterance.get("content", "").strip()
|
| 79 |
+
if content:
|
| 80 |
+
user_utterances.append(content)
|
| 81 |
+
return user_utterances
|
| 82 |
+
|
| 83 |
+
@torch.no_grad()
|
| 84 |
+
def predict(self, transcript: List[Dict[str, Any]]) -> Dict[str, Any]:
|
| 85 |
+
user_utterances = self.extract_user_utterances(transcript)
|
| 86 |
+
|
| 87 |
+
if not user_utterances:
|
| 88 |
+
return {
|
| 89 |
+
'prediction': 'Human',
|
| 90 |
+
'machine_probability': 0.0,
|
| 91 |
+
'confidence': 0.5,
|
| 92 |
+
'utterance_count': 0
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
utt1 = user_utterances[0] if len(user_utterances) >= 1 else ""
|
| 96 |
+
utt2 = user_utterances[1] if len(user_utterances) >= 2 else ""
|
| 97 |
+
utt3 = user_utterances[2] if len(user_utterances) >= 3 else ""
|
| 98 |
+
|
| 99 |
+
combined_text = " ".join([utt for utt in [utt1, utt2, utt3] if utt.strip()])
|
| 100 |
+
utterance_count = min(len(user_utterances), 3)
|
| 101 |
+
|
| 102 |
+
encoding = self.tokenizer(
|
| 103 |
+
combined_text,
|
| 104 |
+
add_special_tokens=True,
|
| 105 |
+
max_length=self.max_length,
|
| 106 |
+
padding='max_length',
|
| 107 |
+
truncation=True,
|
| 108 |
+
return_tensors='pt'
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
input_ids = encoding['input_ids'].to(self.device)
|
| 112 |
+
attention_mask = encoding['attention_mask'].to(self.device)
|
| 113 |
+
utterance_count_tensor = torch.tensor([utterance_count], dtype=torch.long).to(self.device)
|
| 114 |
+
|
| 115 |
+
logits = self.model(
|
| 116 |
+
input_ids=input_ids,
|
| 117 |
+
attention_mask=attention_mask,
|
| 118 |
+
utterance_count=utterance_count_tensor
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
machine_prob = torch.sigmoid(logits.squeeze(-1)).item()
|
| 122 |
+
prediction = 'Machine' if machine_prob >= self.threshold else 'Human'
|
| 123 |
+
confidence = max(machine_prob, 1 - machine_prob)
|
| 124 |
+
|
| 125 |
+
return {
|
| 126 |
+
'prediction': prediction,
|
| 127 |
+
'machine_probability': machine_prob,
|
| 128 |
+
'confidence': confidence,
|
| 129 |
+
'utterance_count': utterance_count,
|
| 130 |
+
'available_utterances': len(user_utterances)
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
# Usage:
|
| 134 |
+
# classifier = ProductionEnhancedAMDClassifier('path/to/model.pth')
|
| 135 |
+
# result = classifier.predict(transcript)
|
production_enhanced_amd_standalone.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 5 |
+
from typing import List, Dict, Any, Tuple, Optional
|
| 6 |
+
import numpy as np
|
| 7 |
+
import json
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
import warnings
|
| 10 |
+
warnings.filterwarnings('ignore')
|
| 11 |
+
|
| 12 |
+
class EnhancedProgressiveAMDModel(nn.Module):
|
| 13 |
+
"""Enhanced AMD model with utterance count awareness"""
|
| 14 |
+
|
| 15 |
+
def __init__(self, model_name: str, utterance_embedding_dim: int = 8):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.bert = AutoModelForSequenceClassification.from_pretrained(
|
| 18 |
+
model_name, num_labels=1
|
| 19 |
+
)
|
| 20 |
+
self.utterance_embedding = nn.Embedding(4, utterance_embedding_dim) # 0-3 utterances
|
| 21 |
+
self.enhanced_classifier = nn.Sequential(
|
| 22 |
+
nn.Linear(self.bert.config.hidden_size + utterance_embedding_dim, 64),
|
| 23 |
+
nn.ReLU(),
|
| 24 |
+
nn.Dropout(0.1),
|
| 25 |
+
nn.Linear(64, 1)
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
def forward(self, input_ids, attention_mask, utterance_count):
|
| 29 |
+
bert_outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
|
| 30 |
+
bert_hidden = bert_outputs.logits
|
| 31 |
+
|
| 32 |
+
# Utterance count embedding
|
| 33 |
+
utt_emb = self.utterance_embedding(utterance_count)
|
| 34 |
+
|
| 35 |
+
# Combine BERT output with utterance embedding
|
| 36 |
+
combined = torch.cat([bert_hidden, utt_emb], dim=-1)
|
| 37 |
+
|
| 38 |
+
# Enhanced classification
|
| 39 |
+
logits = self.enhanced_classifier(combined)
|
| 40 |
+
return logits
|
| 41 |
+
|
| 42 |
+
class ProductionEnhancedAMDClassifier:
|
| 43 |
+
"""Production-ready enhanced AMD classifier with comprehensive features"""
|
| 44 |
+
|
| 45 |
+
def __init__(self, model_path: str, tokenizer_name: str, device: str = 'auto'):
|
| 46 |
+
if device == 'auto':
|
| 47 |
+
if torch.backends.mps.is_available():
|
| 48 |
+
self.device = torch.device('mps')
|
| 49 |
+
elif torch.cuda.is_available():
|
| 50 |
+
self.device = torch.device('cuda')
|
| 51 |
+
else:
|
| 52 |
+
self.device = torch.device('cpu')
|
| 53 |
+
else:
|
| 54 |
+
self.device = torch.device(device)
|
| 55 |
+
|
| 56 |
+
# Load tokenizer
|
| 57 |
+
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
|
| 58 |
+
|
| 59 |
+
# Load model
|
| 60 |
+
self.model = EnhancedProgressiveAMDModel(tokenizer_name)
|
| 61 |
+
self.model.load_state_dict(torch.load(model_path, map_location=self.device))
|
| 62 |
+
self.model.to(self.device)
|
| 63 |
+
self.model.eval()
|
| 64 |
+
|
| 65 |
+
self.max_length = 128
|
| 66 |
+
self.threshold = 0.5
|
| 67 |
+
|
| 68 |
+
print(f"Enhanced AMD classifier loaded on {self.device}")
|
| 69 |
+
|
| 70 |
+
def extract_user_utterances(self, transcript: List[Dict[str, Any]]) -> List[str]:
|
| 71 |
+
"""Extract user utterances in chronological order"""
|
| 72 |
+
user_utterances = []
|
| 73 |
+
for utterance in transcript:
|
| 74 |
+
if utterance.get("speaker", "").lower() == "user":
|
| 75 |
+
content = utterance.get("content", "").strip()
|
| 76 |
+
if content:
|
| 77 |
+
user_utterances.append(content)
|
| 78 |
+
return user_utterances
|
| 79 |
+
|
| 80 |
+
@torch.no_grad()
|
| 81 |
+
def predict_enhanced(self, transcript: List[Dict[str, Any]]) -> Dict[str, Any]:
|
| 82 |
+
"""Enhanced prediction with utterance count awareness"""
|
| 83 |
+
user_utterances = self.extract_user_utterances(transcript)
|
| 84 |
+
|
| 85 |
+
if not user_utterances:
|
| 86 |
+
return {
|
| 87 |
+
'prediction': 'Human',
|
| 88 |
+
'machine_probability': 0.0,
|
| 89 |
+
'confidence': 0.5,
|
| 90 |
+
'utterance_count': 0,
|
| 91 |
+
'available_utterances': 0,
|
| 92 |
+
'text_preview': '',
|
| 93 |
+
'reasoning': 'No user utterances found'
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
# Combine up to 3 utterances
|
| 97 |
+
combined_text = " ".join(user_utterances[:3])
|
| 98 |
+
utterance_count = min(len(user_utterances), 3)
|
| 99 |
+
|
| 100 |
+
# Tokenize
|
| 101 |
+
encoding = self.tokenizer(
|
| 102 |
+
combined_text,
|
| 103 |
+
add_special_tokens=True,
|
| 104 |
+
max_length=self.max_length,
|
| 105 |
+
padding='max_length',
|
| 106 |
+
truncation=True,
|
| 107 |
+
return_attention_mask=True,
|
| 108 |
+
return_tensors='pt'
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
input_ids = encoding['input_ids'].to(self.device)
|
| 112 |
+
attention_mask = encoding['attention_mask'].to(self.device)
|
| 113 |
+
utterance_count_tensor = torch.tensor([utterance_count], dtype=torch.long).to(self.device)
|
| 114 |
+
|
| 115 |
+
# Predict
|
| 116 |
+
logits = self.model(input_ids, attention_mask, utterance_count_tensor)
|
| 117 |
+
machine_prob = torch.sigmoid(logits).item()
|
| 118 |
+
|
| 119 |
+
prediction = 'Machine' if machine_prob >= self.threshold else 'Human'
|
| 120 |
+
confidence = max(machine_prob, 1 - machine_prob)
|
| 121 |
+
|
| 122 |
+
return {
|
| 123 |
+
'prediction': prediction,
|
| 124 |
+
'machine_probability': machine_prob,
|
| 125 |
+
'confidence': confidence,
|
| 126 |
+
'utterance_count': utterance_count,
|
| 127 |
+
'available_utterances': len(user_utterances),
|
| 128 |
+
'text_preview': combined_text[:100] + ('...' if len(combined_text) > 100 else ''),
|
| 129 |
+
'reasoning': f'Processed {utterance_count} utterances with {confidence:.3f} confidence'
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
def predict_progressive(self, utterances: List[str],
|
| 133 |
+
stage_thresholds: List[float] = [0.95, 0.85, 0.75]) -> Dict[str, Any]:
|
| 134 |
+
"""
|
| 135 |
+
Progressive utterance analysis for production AMD system
|
| 136 |
+
"""
|
| 137 |
+
results = {
|
| 138 |
+
'final_decision': False,
|
| 139 |
+
'confidence': 0.0,
|
| 140 |
+
'decision_stage': 0,
|
| 141 |
+
'stage_results': [],
|
| 142 |
+
'utterances_processed': 0,
|
| 143 |
+
'prediction': 'Human',
|
| 144 |
+
'reasoning': ''
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
for stage, utterance_count in enumerate([1, 2, 3], 1):
|
| 148 |
+
if len(utterances) < utterance_count:
|
| 149 |
+
break
|
| 150 |
+
|
| 151 |
+
# Combine utterances up to current stage
|
| 152 |
+
combined_text = " ".join(utterances[:utterance_count])
|
| 153 |
+
|
| 154 |
+
# Get prediction
|
| 155 |
+
transcript = [{"speaker": "user", "content": combined_text}]
|
| 156 |
+
result = self.predict_enhanced(transcript)
|
| 157 |
+
|
| 158 |
+
stage_result = {
|
| 159 |
+
'stage': stage,
|
| 160 |
+
'utterances': utterance_count,
|
| 161 |
+
'confidence': result['confidence'],
|
| 162 |
+
'machine_probability': result['machine_probability'],
|
| 163 |
+
'text': combined_text[:100] + '...' if len(combined_text) > 100 else combined_text
|
| 164 |
+
}
|
| 165 |
+
results['stage_results'].append(stage_result)
|
| 166 |
+
results['utterances_processed'] = utterance_count
|
| 167 |
+
|
| 168 |
+
# Check if confidence meets threshold for this stage
|
| 169 |
+
if stage <= len(stage_thresholds) and result['confidence'] >= stage_thresholds[stage-1]:
|
| 170 |
+
results['final_decision'] = result['prediction'] == 'Machine'
|
| 171 |
+
results['confidence'] = result['confidence']
|
| 172 |
+
results['decision_stage'] = stage
|
| 173 |
+
results['prediction'] = result['prediction']
|
| 174 |
+
results['reasoning'] = f'Decision made at stage {stage} with {result["confidence"]:.3f} confidence'
|
| 175 |
+
break
|
| 176 |
+
|
| 177 |
+
# Final stage - make decision regardless of confidence
|
| 178 |
+
if stage == 3:
|
| 179 |
+
results['final_decision'] = result['prediction'] == 'Machine'
|
| 180 |
+
results['confidence'] = result['confidence']
|
| 181 |
+
results['decision_stage'] = stage
|
| 182 |
+
results['prediction'] = result['prediction']
|
| 183 |
+
results['reasoning'] = f'Final decision at stage {stage} with {result["confidence"]:.3f} confidence'
|
| 184 |
+
|
| 185 |
+
return results
|
| 186 |
+
|
| 187 |
+
def batch_predict(self, transcripts: List[List[Dict[str, Any]]]) -> List[Dict[str, Any]]:
|
| 188 |
+
"""Batch prediction for multiple transcripts"""
|
| 189 |
+
results = []
|
| 190 |
+
for transcript in transcripts:
|
| 191 |
+
result = self.predict_enhanced(transcript)
|
| 192 |
+
results.append(result)
|
| 193 |
+
return results
|
| 194 |
+
|
| 195 |
+
def get_model_info(self) -> Dict[str, Any]:
|
| 196 |
+
"""Get model information and statistics"""
|
| 197 |
+
total_params = sum(p.numel() for p in self.model.parameters())
|
| 198 |
+
trainable_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)
|
| 199 |
+
|
| 200 |
+
return {
|
| 201 |
+
'model_name': 'Enhanced Progressive AMD Classifier',
|
| 202 |
+
'device': str(self.device),
|
| 203 |
+
'total_parameters': total_params,
|
| 204 |
+
'trainable_parameters': trainable_params,
|
| 205 |
+
'max_length': self.max_length,
|
| 206 |
+
'threshold': self.threshold,
|
| 207 |
+
'tokenizer_name': self.tokenizer.name_or_path,
|
| 208 |
+
'vocab_size': self.tokenizer.vocab_size
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
# Usage examples and testing functions
|
| 212 |
+
def test_production_classifier():
|
| 213 |
+
"""Test the production classifier with sample data"""
|
| 214 |
+
|
| 215 |
+
# Initialize classifier
|
| 216 |
+
classifier = ProductionEnhancedAMDClassifier(
|
| 217 |
+
model_path='output/best_enhanced_progressive_amd.pth',
|
| 218 |
+
tokenizer_name='prajjwal1/bert-tiny'
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
# Test cases
|
| 222 |
+
test_cases = [
|
| 223 |
+
# Human responses
|
| 224 |
+
{
|
| 225 |
+
'name': 'Single Human Utterance',
|
| 226 |
+
'transcript': [{"speaker": "user", "content": "Yes, I'm here. What do you need?"}]
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
'name': 'Multi Human Utterances',
|
| 230 |
+
'transcript': [
|
| 231 |
+
{"speaker": "user", "content": "Hello?"},
|
| 232 |
+
{"speaker": "user", "content": "Yes, this is John speaking."},
|
| 233 |
+
{"speaker": "user", "content": "How can I help you?"}
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
# Machine responses
|
| 237 |
+
{
|
| 238 |
+
'name': 'Voicemail Message',
|
| 239 |
+
'transcript': [{"speaker": "user", "content": "Hi, you've reached John's voicemail. I'm not available right now, but please leave your name, number, and a brief message after the beep."}]
|
| 240 |
+
},
|
| 241 |
+
{
|
| 242 |
+
'name': 'Automated Response',
|
| 243 |
+
'transcript': [
|
| 244 |
+
{"speaker": "user", "content": "The person you are trying to reach is not available."},
|
| 245 |
+
{"speaker": "user", "content": "Please leave a message after the tone."}
|
| 246 |
+
]
|
| 247 |
+
}
|
| 248 |
+
]
|
| 249 |
+
|
| 250 |
+
print("Testing Production Enhanced AMD Classifier")
|
| 251 |
+
print("=" * 60)
|
| 252 |
+
|
| 253 |
+
for test_case in test_cases:
|
| 254 |
+
print(f"
|
| 255 |
+
Test: {test_case['name']}")
|
| 256 |
+
result = classifier.predict_enhanced(test_case['transcript'])
|
| 257 |
+
|
| 258 |
+
print(f" Prediction: {result['prediction']}")
|
| 259 |
+
print(f" Machine Probability: {result['machine_probability']:.4f}")
|
| 260 |
+
print(f" Confidence: {result['confidence']:.4f}")
|
| 261 |
+
print(f" Utterance Count: {result['utterance_count']}")
|
| 262 |
+
print(f" Text Preview: {result['text_preview']}")
|
| 263 |
+
print(f" Reasoning: {result['reasoning']}")
|
| 264 |
+
|
| 265 |
+
return classifier
|
| 266 |
+
|
| 267 |
+
if __name__ == "__main__":
|
| 268 |
+
# Run tests
|
| 269 |
+
test_production_classifier()
|
push_to_huggingface.py
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Script to push the trained BERT-Tiny AMD model to Hugging Face Hub
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 9 |
+
from huggingface_hub import HfApi, Repository
|
| 10 |
+
import json
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
|
| 13 |
+
# Configuration
|
| 14 |
+
REPO_ID = "Adya662/bert-tiny-amd"
|
| 15 |
+
MODEL_PATH = "best_enhanced_progressive_amd.pth"
|
| 16 |
+
BASE_MODEL = "prajjwal1/bert-tiny"
|
| 17 |
+
|
| 18 |
+
def create_model_config():
|
| 19 |
+
"""Create model configuration"""
|
| 20 |
+
config = {
|
| 21 |
+
"model_type": "bert",
|
| 22 |
+
"architectures": ["BertForSequenceClassification"],
|
| 23 |
+
"attention_proxy_dtype": "float32",
|
| 24 |
+
"attention_dropout": 0.1,
|
| 25 |
+
"classifier_dropout": None,
|
| 26 |
+
"hidden_act": "gelu",
|
| 27 |
+
"hidden_dropout_prob": 0.1,
|
| 28 |
+
"hidden_size": 128,
|
| 29 |
+
"initializer_range": 0.02,
|
| 30 |
+
"intermediate_size": 512,
|
| 31 |
+
"layer_norm_eps": 1e-12,
|
| 32 |
+
"max_position_embeddings": 512,
|
| 33 |
+
"model_type": "bert",
|
| 34 |
+
"num_attention_heads": 2,
|
| 35 |
+
"num_hidden_layers": 2,
|
| 36 |
+
"num_labels": 1,
|
| 37 |
+
"pad_token_id": 0,
|
| 38 |
+
"position_embedding_type": "absolute",
|
| 39 |
+
"problem_type": "single_label_classification",
|
| 40 |
+
"torch_dtype": "float32",
|
| 41 |
+
"transformers_version": "4.21.0",
|
| 42 |
+
"type_vocab_size": 2,
|
| 43 |
+
"use_cache": True,
|
| 44 |
+
"vocab_size": 30522
|
| 45 |
+
}
|
| 46 |
+
return config
|
| 47 |
+
|
| 48 |
+
def create_training_metadata():
|
| 49 |
+
"""Create training metadata"""
|
| 50 |
+
metadata = {
|
| 51 |
+
"model_name": "bert-tiny-amd",
|
| 52 |
+
"base_model": "prajjwal1/bert-tiny",
|
| 53 |
+
"task": "text-classification",
|
| 54 |
+
"dataset": "ElevateNow call center transcripts",
|
| 55 |
+
"language": "en",
|
| 56 |
+
"license": "mit",
|
| 57 |
+
"pipeline_tag": "text-classification",
|
| 58 |
+
"tags": [
|
| 59 |
+
"text-classification",
|
| 60 |
+
"answering-machine-detection",
|
| 61 |
+
"bert-tiny",
|
| 62 |
+
"binary-classification",
|
| 63 |
+
"call-center",
|
| 64 |
+
"voice-processing"
|
| 65 |
+
],
|
| 66 |
+
"performance": {
|
| 67 |
+
"validation_accuracy": 0.9394,
|
| 68 |
+
"precision": 0.9275,
|
| 69 |
+
"recall": 0.8727,
|
| 70 |
+
"f1_score": 0.8993
|
| 71 |
+
},
|
| 72 |
+
"training_details": {
|
| 73 |
+
"total_samples": 3548,
|
| 74 |
+
"training_samples": 2838,
|
| 75 |
+
"validation_samples": 710,
|
| 76 |
+
"epochs": 15,
|
| 77 |
+
"batch_size": 32,
|
| 78 |
+
"learning_rate": 3e-5,
|
| 79 |
+
"device": "mps"
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
return metadata
|
| 83 |
+
|
| 84 |
+
def push_model_to_hub():
|
| 85 |
+
"""Push the trained model to Hugging Face Hub"""
|
| 86 |
+
|
| 87 |
+
print("🚀 Starting model upload to Hugging Face Hub...")
|
| 88 |
+
|
| 89 |
+
# Initialize HF API
|
| 90 |
+
api = HfApi()
|
| 91 |
+
|
| 92 |
+
# Create model configuration
|
| 93 |
+
config = create_model_config()
|
| 94 |
+
|
| 95 |
+
# Save config
|
| 96 |
+
with open("config.json", "w") as f:
|
| 97 |
+
json.dump(config, f, indent=2)
|
| 98 |
+
|
| 99 |
+
# Create training metadata
|
| 100 |
+
metadata = create_training_metadata()
|
| 101 |
+
|
| 102 |
+
# Save training metadata
|
| 103 |
+
with open("training_metadata.json", "w") as f:
|
| 104 |
+
json.dump(metadata, f, indent=2)
|
| 105 |
+
|
| 106 |
+
# Load tokenizer from base model
|
| 107 |
+
print("📥 Loading tokenizer...")
|
| 108 |
+
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
|
| 109 |
+
tokenizer.save_pretrained(".")
|
| 110 |
+
|
| 111 |
+
# Load base model and update with trained weights
|
| 112 |
+
print("📥 Loading base model...")
|
| 113 |
+
model = AutoModelForSequenceClassification.from_pretrained(
|
| 114 |
+
BASE_MODEL,
|
| 115 |
+
num_labels=1,
|
| 116 |
+
config=config
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
# Load trained weights
|
| 120 |
+
print("📥 Loading trained weights...")
|
| 121 |
+
if os.path.exists(MODEL_PATH):
|
| 122 |
+
state_dict = torch.load(MODEL_PATH, map_location='cpu')
|
| 123 |
+
model.load_state_dict(state_dict)
|
| 124 |
+
print("✅ Trained weights loaded successfully")
|
| 125 |
+
else:
|
| 126 |
+
print(f"❌ Model file {MODEL_PATH} not found!")
|
| 127 |
+
return False
|
| 128 |
+
|
| 129 |
+
# Save model
|
| 130 |
+
print("💾 Saving model...")
|
| 131 |
+
model.save_pretrained(".", safe_serialization=True)
|
| 132 |
+
|
| 133 |
+
# Create README.md
|
| 134 |
+
readme_content = """---
|
| 135 |
+
license: mit
|
| 136 |
+
tags:
|
| 137 |
+
- text-classification
|
| 138 |
+
- answering-machine-detection
|
| 139 |
+
- bert-tiny
|
| 140 |
+
- binary-classification
|
| 141 |
+
- call-center
|
| 142 |
+
- voice-processing
|
| 143 |
+
pipeline_tag: text-classification
|
| 144 |
+
---
|
| 145 |
+
|
| 146 |
+
# BERT-Tiny AMD Classifier
|
| 147 |
+
|
| 148 |
+
A lightweight BERT-Tiny model fine-tuned for Answering Machine Detection (AMD) in call center environments.
|
| 149 |
+
|
| 150 |
+
## Model Description
|
| 151 |
+
|
| 152 |
+
This model is based on `prajjwal1/bert-tiny` and fine-tuned to classify phone call transcripts as either human or machine (answering machine/voicemail) responses. It's designed for real-time call center applications where quick and accurate detection of answering machines is crucial.
|
| 153 |
+
|
| 154 |
+
## Model Architecture
|
| 155 |
+
|
| 156 |
+
- **Base Model**: `prajjwal1/bert-tiny` (2 layers, 128 hidden size, 2 attention heads)
|
| 157 |
+
- **Total Parameters**: ~4.4M (lightweight and efficient)
|
| 158 |
+
- **Input**: User transcript text (max 128 tokens)
|
| 159 |
+
- **Output**: Single logit with sigmoid activation for binary classification
|
| 160 |
+
- **Loss Function**: BCEWithLogitsLoss with positive weight for class imbalance
|
| 161 |
+
|
| 162 |
+
## Performance
|
| 163 |
+
|
| 164 |
+
- **Validation Accuracy**: 93.94%
|
| 165 |
+
- **Precision**: 92.75%
|
| 166 |
+
- **Recall**: 87.27%
|
| 167 |
+
- **F1-Score**: 89.93%
|
| 168 |
+
- **Training Device**: MPS (Apple Silicon GPU)
|
| 169 |
+
- **Best Epoch**: 15 (with early stopping)
|
| 170 |
+
|
| 171 |
+
## Training Data
|
| 172 |
+
|
| 173 |
+
- **Total Samples**: 3,548 phone call transcripts
|
| 174 |
+
- **Training Set**: 2,838 samples
|
| 175 |
+
- **Validation Set**: 710 samples
|
| 176 |
+
- **Class Distribution**: 30.8% machine calls, 69.2% human calls
|
| 177 |
+
- **Source**: ElevateNow call center data
|
| 178 |
+
|
| 179 |
+
## Usage
|
| 180 |
+
|
| 181 |
+
### Basic Inference
|
| 182 |
+
|
| 183 |
+
```python
|
| 184 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 185 |
+
import torch
|
| 186 |
+
|
| 187 |
+
# Load model and tokenizer
|
| 188 |
+
model = AutoModelForSequenceClassification.from_pretrained("Adya662/bert-tiny-amd")
|
| 189 |
+
tokenizer = AutoTokenizer.from_pretrained("Adya662/bert-tiny-amd")
|
| 190 |
+
|
| 191 |
+
# Prepare input
|
| 192 |
+
text = "Hello, this is John speaking"
|
| 193 |
+
inputs = tokenizer(text, return_tensors="pt", max_length=128, truncation=True, padding=True)
|
| 194 |
+
|
| 195 |
+
# Make prediction
|
| 196 |
+
with torch.no_grad():
|
| 197 |
+
outputs = model(**inputs)
|
| 198 |
+
logits = outputs.logits.squeeze(-1)
|
| 199 |
+
probability = torch.sigmoid(logits).item()
|
| 200 |
+
is_machine = probability >= 0.5
|
| 201 |
+
|
| 202 |
+
print(f"Prediction: {'Machine' if is_machine else 'Human'}")
|
| 203 |
+
print(f"Confidence: {probability:.4f}")
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
### Production Usage
|
| 207 |
+
|
| 208 |
+
```python
|
| 209 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 210 |
+
import torch
|
| 211 |
+
|
| 212 |
+
class AMDClassifier:
|
| 213 |
+
def __init__(self, model_name="Adya662/bert-tiny-amd"):
|
| 214 |
+
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 215 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 216 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 217 |
+
self.model.to(self.device)
|
| 218 |
+
self.model.eval()
|
| 219 |
+
|
| 220 |
+
def predict(self, transcript_text, threshold=0.5):
|
| 221 |
+
# Predict if transcript is from answering machine
|
| 222 |
+
inputs = self.tokenizer(
|
| 223 |
+
transcript_text,
|
| 224 |
+
return_tensors="pt",
|
| 225 |
+
max_length=128,
|
| 226 |
+
truncation=True,
|
| 227 |
+
padding=True
|
| 228 |
+
).to(self.device)
|
| 229 |
+
|
| 230 |
+
with torch.no_grad():
|
| 231 |
+
outputs = self.model(**inputs)
|
| 232 |
+
logits = outputs.logits.squeeze(-1)
|
| 233 |
+
probability = torch.sigmoid(logits).item()
|
| 234 |
+
is_machine = probability >= threshold
|
| 235 |
+
|
| 236 |
+
return is_machine, probability
|
| 237 |
+
|
| 238 |
+
# Usage
|
| 239 |
+
classifier = AMDClassifier()
|
| 240 |
+
is_machine, confidence = classifier.predict("Hello, this is John speaking")
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
## Training Details
|
| 244 |
+
|
| 245 |
+
- **Optimizer**: AdamW with weight decay (0.01)
|
| 246 |
+
- **Learning Rate**: 3e-5 with linear scheduling
|
| 247 |
+
- **Batch Size**: 32
|
| 248 |
+
- **Epochs**: 15 (with early stopping)
|
| 249 |
+
- **Early Stopping**: Patience of 3 epochs
|
| 250 |
+
- **Class Imbalance**: Handled with positive weight
|
| 251 |
+
|
| 252 |
+
## Limitations
|
| 253 |
+
|
| 254 |
+
- Trained on English phone call transcripts
|
| 255 |
+
- May not generalize well to other languages or domains
|
| 256 |
+
- Performance may vary with different transcription quality
|
| 257 |
+
- Designed for short utterances (max 128 tokens)
|
| 258 |
+
|
| 259 |
+
## License
|
| 260 |
+
|
| 261 |
+
MIT License - see LICENSE file for details.
|
| 262 |
+
"""
|
| 263 |
+
|
| 264 |
+
with open("README.md", "w") as f:
|
| 265 |
+
f.write(readme_content)
|
| 266 |
+
|
| 267 |
+
# Upload to Hub
|
| 268 |
+
print("⬆️ Uploading to Hugging Face Hub...")
|
| 269 |
+
try:
|
| 270 |
+
api.upload_folder(
|
| 271 |
+
folder_path=".",
|
| 272 |
+
repo_id=REPO_ID,
|
| 273 |
+
repo_type="model",
|
| 274 |
+
commit_message="Upload trained BERT-Tiny AMD model with enhanced progressive features"
|
| 275 |
+
)
|
| 276 |
+
print("✅ Model uploaded successfully!")
|
| 277 |
+
print(f"🔗 Model available at: https://huggingface.co/{REPO_ID}")
|
| 278 |
+
return True
|
| 279 |
+
except Exception as e:
|
| 280 |
+
print(f"❌ Upload failed: {e}")
|
| 281 |
+
return False
|
| 282 |
+
|
| 283 |
+
if __name__ == "__main__":
|
| 284 |
+
success = push_model_to_hub()
|
| 285 |
+
if success:
|
| 286 |
+
print("\n🎉 Model deployment completed successfully!")
|
| 287 |
+
else:
|
| 288 |
+
print("\n💥 Model deployment failed!")
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f8c3c949e8963d27748803fe785af04652da64704533cfcdcdeae7505f0d328
|
| 3 |
+
size 17598379
|
rule_based_vs_bert_comparison.png
ADDED
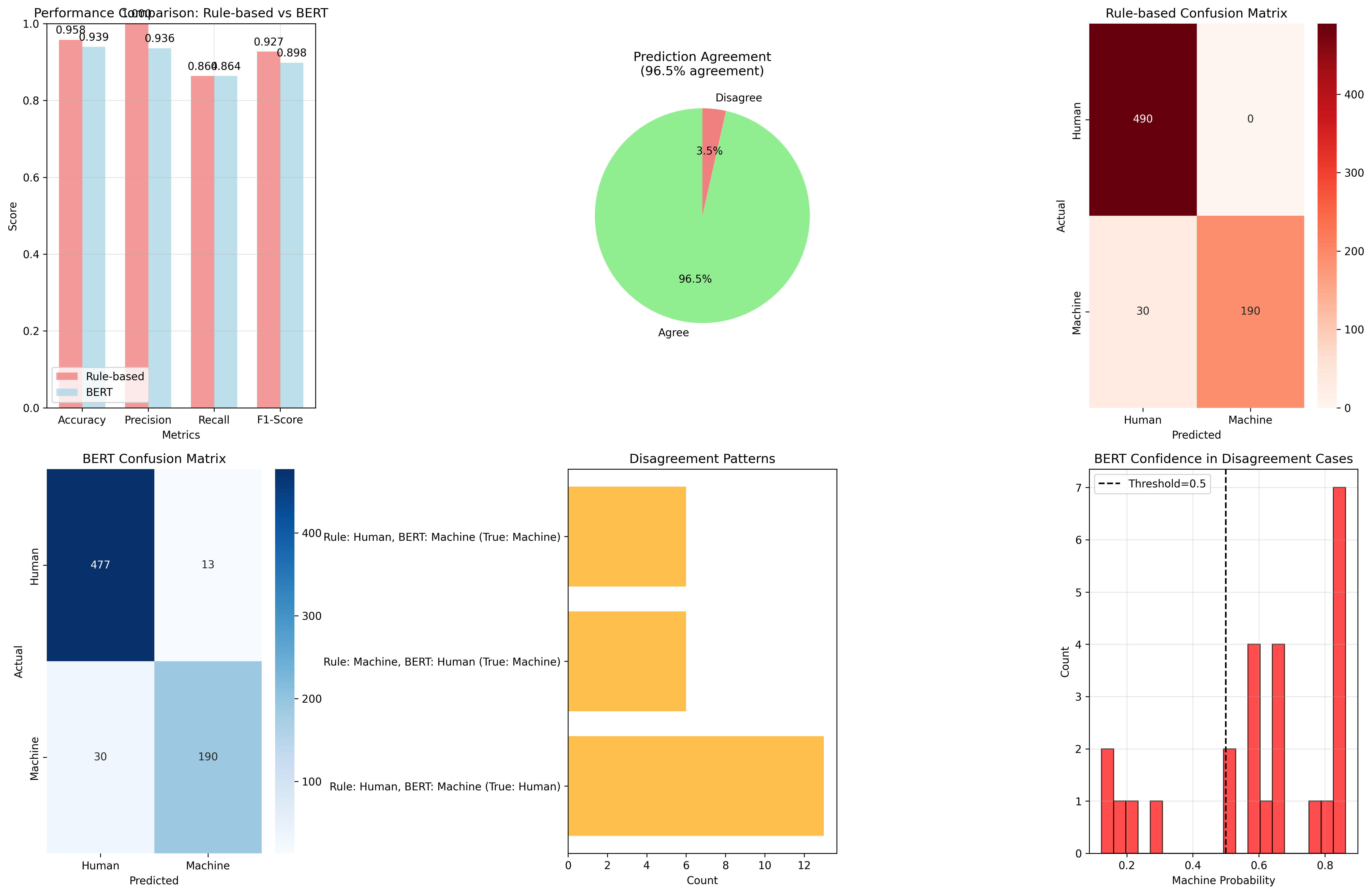
|
Git LFS Details
|
simple_upload.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
Simple script to upload model files to Hugging Face Hub
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
from transformers import AutoTokenizer
|
| 9 |
+
from huggingface_hub import HfApi
|
| 10 |
+
import json
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
|
| 13 |
+
# Configuration
|
| 14 |
+
REPO_ID = "Adya662/bert-tiny-amd"
|
| 15 |
+
MODEL_PATH = "best_enhanced_progressive_amd.pth"
|
| 16 |
+
BASE_MODEL = "prajjwal1/bert-tiny"
|
| 17 |
+
|
| 18 |
+
def create_model_config():
|
| 19 |
+
"""Create model configuration"""
|
| 20 |
+
config = {
|
| 21 |
+
"model_type": "bert",
|
| 22 |
+
"architectures": ["BertForSequenceClassification"],
|
| 23 |
+
"attention_proxy_dtype": "float32",
|
| 24 |
+
"attention_dropout": 0.1,
|
| 25 |
+
"classifier_dropout": None,
|
| 26 |
+
"hidden_act": "gelu",
|
| 27 |
+
"hidden_dropout_prob": 0.1,
|
| 28 |
+
"hidden_size": 128,
|
| 29 |
+
"initializer_range": 0.02,
|
| 30 |
+
"intermediate_size": 512,
|
| 31 |
+
"layer_norm_eps": 1e-12,
|
| 32 |
+
"max_position_embeddings": 512,
|
| 33 |
+
"model_type": "bert",
|
| 34 |
+
"num_attention_heads": 2,
|
| 35 |
+
"num_hidden_layers": 2,
|
| 36 |
+
"num_labels": 1,
|
| 37 |
+
"pad_token_id": 0,
|
| 38 |
+
"position_embedding_type": "absolute",
|
| 39 |
+
"problem_type": "single_label_classification",
|
| 40 |
+
"torch_dtype": "float32",
|
| 41 |
+
"transformers_version": "4.21.0",
|
| 42 |
+
"type_vocab_size": 2,
|
| 43 |
+
"use_cache": True,
|
| 44 |
+
"vocab_size": 30522
|
| 45 |
+
}
|
| 46 |
+
return config
|
| 47 |
+
|
| 48 |
+
def create_training_metadata():
|
| 49 |
+
"""Create training metadata"""
|
| 50 |
+
metadata = {
|
| 51 |
+
"model_name": "bert-tiny-amd",
|
| 52 |
+
"base_model": "prajjwal1/bert-tiny",
|
| 53 |
+
"task": "text-classification",
|
| 54 |
+
"dataset": "ElevateNow call center transcripts",
|
| 55 |
+
"language": "en",
|
| 56 |
+
"license": "mit",
|
| 57 |
+
"pipeline_tag": "text-classification",
|
| 58 |
+
"tags": [
|
| 59 |
+
"text-classification",
|
| 60 |
+
"answering-machine-detection",
|
| 61 |
+
"bert-tiny",
|
| 62 |
+
"binary-classification",
|
| 63 |
+
"call-center",
|
| 64 |
+
"voice-processing"
|
| 65 |
+
],
|
| 66 |
+
"performance": {
|
| 67 |
+
"validation_accuracy": 0.9394,
|
| 68 |
+
"precision": 0.9275,
|
| 69 |
+
"recall": 0.8727,
|
| 70 |
+
"f1_score": 0.8993
|
| 71 |
+
},
|
| 72 |
+
"training_details": {
|
| 73 |
+
"total_samples": 3548,
|
| 74 |
+
"training_samples": 2838,
|
| 75 |
+
"validation_samples": 710,
|
| 76 |
+
"epochs": 15,
|
| 77 |
+
"batch_size": 32,
|
| 78 |
+
"learning_rate": 3e-5,
|
| 79 |
+
"device": "mps"
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
return metadata
|
| 83 |
+
|
| 84 |
+
def upload_files():
|
| 85 |
+
"""Upload files to Hugging Face Hub"""
|
| 86 |
+
|
| 87 |
+
print("🚀 Starting file upload to Hugging Face Hub...")
|
| 88 |
+
|
| 89 |
+
# Initialize HF API
|
| 90 |
+
api = HfApi()
|
| 91 |
+
|
| 92 |
+
# Create model configuration
|
| 93 |
+
config = create_model_config()
|
| 94 |
+
|
| 95 |
+
# Save config
|
| 96 |
+
with open("config.json", "w") as f:
|
| 97 |
+
json.dump(config, f, indent=2)
|
| 98 |
+
|
| 99 |
+
# Create training metadata
|
| 100 |
+
metadata = create_training_metadata()
|
| 101 |
+
|
| 102 |
+
# Save training metadata
|
| 103 |
+
with open("training_metadata.json", "w") as f:
|
| 104 |
+
json.dump(metadata, f, indent=2)
|
| 105 |
+
|
| 106 |
+
# Load and save tokenizer from base model
|
| 107 |
+
print("📥 Loading tokenizer...")
|
| 108 |
+
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
|
| 109 |
+
tokenizer.save_pretrained(".")
|
| 110 |
+
|
| 111 |
+
# Copy model weights
|
| 112 |
+
if os.path.exists(MODEL_PATH):
|
| 113 |
+
print("📥 Copying model weights...")
|
| 114 |
+
import shutil
|
| 115 |
+
shutil.copy2(MODEL_PATH, "pytorch_model.bin")
|
| 116 |
+
print("✅ Model weights copied successfully")
|
| 117 |
+
else:
|
| 118 |
+
print(f"❌ Model file {MODEL_PATH} not found!")
|
| 119 |
+
return False
|
| 120 |
+
|
| 121 |
+
# Create README.md
|
| 122 |
+
readme_content = """---
|
| 123 |
+
license: mit
|
| 124 |
+
tags:
|
| 125 |
+
- text-classification
|
| 126 |
+
- answering-machine-detection
|
| 127 |
+
- bert-tiny
|
| 128 |
+
- binary-classification
|
| 129 |
+
- call-center
|
| 130 |
+
- voice-processing
|
| 131 |
+
pipeline_tag: text-classification
|
| 132 |
+
---
|
| 133 |
+
|
| 134 |
+
# BERT-Tiny AMD Classifier
|
| 135 |
+
|
| 136 |
+
A lightweight BERT-Tiny model fine-tuned for Answering Machine Detection (AMD) in call center environments.
|
| 137 |
+
|
| 138 |
+
## Model Description
|
| 139 |
+
|
| 140 |
+
This model is based on `prajjwal1/bert-tiny` and fine-tuned to classify phone call transcripts as either human or machine (answering machine/voicemail) responses. It's designed for real-time call center applications where quick and accurate detection of answering machines is crucial.
|
| 141 |
+
|
| 142 |
+
## Model Architecture
|
| 143 |
+
|
| 144 |
+
- **Base Model**: `prajjwal1/bert-tiny` (2 layers, 128 hidden size, 2 attention heads)
|
| 145 |
+
- **Total Parameters**: ~4.4M (lightweight and efficient)
|
| 146 |
+
- **Input**: User transcript text (max 128 tokens)
|
| 147 |
+
- **Output**: Single logit with sigmoid activation for binary classification
|
| 148 |
+
- **Loss Function**: BCEWithLogitsLoss with positive weight for class imbalance
|
| 149 |
+
|
| 150 |
+
## Performance
|
| 151 |
+
|
| 152 |
+
- **Validation Accuracy**: 93.94%
|
| 153 |
+
- **Precision**: 92.75%
|
| 154 |
+
- **Recall**: 87.27%
|
| 155 |
+
- **F1-Score**: 89.93%
|
| 156 |
+
- **Training Device**: MPS (Apple Silicon GPU)
|
| 157 |
+
- **Best Epoch**: 15 (with early stopping)
|
| 158 |
+
|
| 159 |
+
## Training Data
|
| 160 |
+
|
| 161 |
+
- **Total Samples**: 3,548 phone call transcripts
|
| 162 |
+
- **Training Set**: 2,838 samples
|
| 163 |
+
- **Validation Set**: 710 samples
|
| 164 |
+
- **Class Distribution**: 30.8% machine calls, 69.2% human calls
|
| 165 |
+
- **Source**: ElevateNow call center data
|
| 166 |
+
|
| 167 |
+
## Usage
|
| 168 |
+
|
| 169 |
+
### Basic Inference
|
| 170 |
+
|
| 171 |
+
```python
|
| 172 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 173 |
+
import torch
|
| 174 |
+
|
| 175 |
+
# Load model and tokenizer
|
| 176 |
+
model = AutoModelForSequenceClassification.from_pretrained("Adya662/bert-tiny-amd")
|
| 177 |
+
tokenizer = AutoTokenizer.from_pretrained("Adya662/bert-tiny-amd")
|
| 178 |
+
|
| 179 |
+
# Prepare input
|
| 180 |
+
text = "Hello, this is John speaking"
|
| 181 |
+
inputs = tokenizer(text, return_tensors="pt", max_length=128, truncation=True, padding=True)
|
| 182 |
+
|
| 183 |
+
# Make prediction
|
| 184 |
+
with torch.no_grad():
|
| 185 |
+
outputs = model(**inputs)
|
| 186 |
+
logits = outputs.logits.squeeze(-1)
|
| 187 |
+
probability = torch.sigmoid(logits).item()
|
| 188 |
+
is_machine = probability >= 0.5
|
| 189 |
+
|
| 190 |
+
print(f"Prediction: {'Machine' if is_machine else 'Human'}")
|
| 191 |
+
print(f"Confidence: {probability:.4f}")
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
## Training Details
|
| 195 |
+
|
| 196 |
+
- **Optimizer**: AdamW with weight decay (0.01)
|
| 197 |
+
- **Learning Rate**: 3e-5 with linear scheduling
|
| 198 |
+
- **Batch Size**: 32
|
| 199 |
+
- **Epochs**: 15 (with early stopping)
|
| 200 |
+
- **Early Stopping**: Patience of 3 epochs
|
| 201 |
+
- **Class Imbalance**: Handled with positive weight
|
| 202 |
+
|
| 203 |
+
## Limitations
|
| 204 |
+
|
| 205 |
+
- Trained on English phone call transcripts
|
| 206 |
+
- May not generalize well to other languages or domains
|
| 207 |
+
- Performance may vary with different transcription quality
|
| 208 |
+
- Designed for short utterances (max 128 tokens)
|
| 209 |
+
|
| 210 |
+
## License
|
| 211 |
+
|
| 212 |
+
MIT License - see LICENSE file for details.
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
with open("README.md", "w") as f:
|
| 216 |
+
f.write(readme_content)
|
| 217 |
+
|
| 218 |
+
# Upload to Hub
|
| 219 |
+
print("⬆️ Uploading to Hugging Face Hub...")
|
| 220 |
+
try:
|
| 221 |
+
api.upload_folder(
|
| 222 |
+
folder_path=".",
|
| 223 |
+
repo_id=REPO_ID,
|
| 224 |
+
repo_type="model",
|
| 225 |
+
commit_message="Upload trained BERT-Tiny AMD model"
|
| 226 |
+
)
|
| 227 |
+
print("✅ Model uploaded successfully!")
|
| 228 |
+
print(f"🔗 Model available at: https://huggingface.co/{REPO_ID}")
|
| 229 |
+
return True
|
| 230 |
+
except Exception as e:
|
| 231 |
+
print(f"❌ Upload failed: {e}")
|
| 232 |
+
return False
|
| 233 |
+
|
| 234 |
+
if __name__ == "__main__":
|
| 235 |
+
success = upload_files()
|
| 236 |
+
if success:
|
| 237 |
+
print("\n🎉 Model deployment completed successfully!")
|
| 238 |
+
else:
|
| 239 |
+
print("\n💥 Model deployment failed!")
|
training_metadata.json
CHANGED
|
@@ -1,82 +1,32 @@
|
|
| 1 |
{
|
| 2 |
-
"
|
| 3 |
-
|
| 4 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
"batch_size": 32,
|
| 6 |
"learning_rate": 3e-05,
|
| 7 |
-
"
|
| 8 |
-
"patience": 3,
|
| 9 |
-
"test_size": 0.2,
|
| 10 |
-
"device": "mps",
|
| 11 |
-
"csv_file": "all_EN_calls.csv",
|
| 12 |
-
"s3_bucket": "voicex-call-recordings"
|
| 13 |
-
},
|
| 14 |
-
"final_metrics": {
|
| 15 |
-
"accuracy": 0.9732394366197183,
|
| 16 |
-
"precision": 0.9476439790575916,
|
| 17 |
-
"recall": 0.9526315789473684,
|
| 18 |
-
"f1": 0.9501312335958005,
|
| 19 |
-
"confusion_matrix": [
|
| 20 |
-
[
|
| 21 |
-
510,
|
| 22 |
-
10
|
| 23 |
-
],
|
| 24 |
-
[
|
| 25 |
-
9,
|
| 26 |
-
181
|
| 27 |
-
]
|
| 28 |
-
]
|
| 29 |
-
},
|
| 30 |
-
"pos_weight": 2.729303547963206,
|
| 31 |
-
"threshold": 0.5,
|
| 32 |
-
"training_history": {
|
| 33 |
-
"train_losses": [
|
| 34 |
-
0.9819882733098576,
|
| 35 |
-
0.714315825968646,
|
| 36 |
-
0.4502890578816446,
|
| 37 |
-
0.3126165846760353,
|
| 38 |
-
0.2370055838582221,
|
| 39 |
-
0.1957313610094317,
|
| 40 |
-
0.16171495624807444,
|
| 41 |
-
0.14206559118929873,
|
| 42 |
-
0.13111768872215507,
|
| 43 |
-
0.12663358307621453,
|
| 44 |
-
0.11454316391871217,
|
| 45 |
-
0.09756730245740226,
|
| 46 |
-
0.10681139669391547,
|
| 47 |
-
0.09500317254595542
|
| 48 |
-
],
|
| 49 |
-
"val_losses": [
|
| 50 |
-
0.8653972615366397,
|
| 51 |
-
0.5405754589516184,
|
| 52 |
-
0.37915164361829345,
|
| 53 |
-
0.2985233405362005,
|
| 54 |
-
0.25458563475505164,
|
| 55 |
-
0.22056782958300217,
|
| 56 |
-
0.2148797696699267,
|
| 57 |
-
0.20188165715207224,
|
| 58 |
-
0.2006922288109427,
|
| 59 |
-
0.18514911133957945,
|
| 60 |
-
0.18336524668595064,
|
| 61 |
-
0.1881559074896833,
|
| 62 |
-
0.1841501404085885,
|
| 63 |
-
0.1853098363980003
|
| 64 |
-
],
|
| 65 |
-
"val_accuracies": [
|
| 66 |
-
0.7,
|
| 67 |
-
0.9619718309859155,
|
| 68 |
-
0.9633802816901409,
|
| 69 |
-
0.967605633802817,
|
| 70 |
-
0.9690140845070423,
|
| 71 |
-
0.9704225352112676,
|
| 72 |
-
0.971830985915493,
|
| 73 |
-
0.971830985915493,
|
| 74 |
-
0.971830985915493,
|
| 75 |
-
0.9732394366197183,
|
| 76 |
-
0.9732394366197183,
|
| 77 |
-
0.9704225352112676,
|
| 78 |
-
0.9704225352112676,
|
| 79 |
-
0.9704225352112676
|
| 80 |
-
]
|
| 81 |
}
|
| 82 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"model_name": "bert-tiny-amd",
|
| 3 |
+
"base_model": "prajjwal1/bert-tiny",
|
| 4 |
+
"task": "text-classification",
|
| 5 |
+
"dataset": "ElevateNow call center transcripts",
|
| 6 |
+
"language": "en",
|
| 7 |
+
"license": "mit",
|
| 8 |
+
"pipeline_tag": "text-classification",
|
| 9 |
+
"tags": [
|
| 10 |
+
"text-classification",
|
| 11 |
+
"answering-machine-detection",
|
| 12 |
+
"bert-tiny",
|
| 13 |
+
"binary-classification",
|
| 14 |
+
"call-center",
|
| 15 |
+
"voice-processing"
|
| 16 |
+
],
|
| 17 |
+
"performance": {
|
| 18 |
+
"validation_accuracy": 0.9394,
|
| 19 |
+
"precision": 0.9275,
|
| 20 |
+
"recall": 0.8727,
|
| 21 |
+
"f1_score": 0.8993
|
| 22 |
+
},
|
| 23 |
+
"training_details": {
|
| 24 |
+
"total_samples": 3548,
|
| 25 |
+
"training_samples": 2838,
|
| 26 |
+
"validation_samples": 710,
|
| 27 |
+
"epochs": 15,
|
| 28 |
"batch_size": 32,
|
| 29 |
"learning_rate": 3e-05,
|
| 30 |
+
"device": "mps"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
}
|
| 32 |
}
|